By Thane Ruthenis
This was a prize-winning entry into the Essay Competition on the Automation of Wisdom and Philosophy.
Summary
Philosophy and wisdom, and the processes underlying them, currently lack a proper operationalization: a set of robust formal or semi-formal definitions. If such definitions were found, they could be used as the foundation for a strong methodological framework. Such a framework would provide clear guidelines for how to engage in high-quality philosophical/wise reasoning and how to evaluate whether a given attempt at philosophy or wisdom was a success or a failure.
To address that, I provide candidate definitions for philosophy and wisdom, relate them to intuitive examples of philosophical and wise reasoning, and offer a tentative formalization of both concepts. The motivation for this is my belief that the lack of proper operationalization is the main obstacle to both (1) scaling up the work done in these domains (i. e., creating a bigger ecosystem that would naturally attract funding), and (2) automating them.
The discussion of philosophy focuses on the tentative formalization of a specific algorithm that I believe is central to philosophical thinking: the algorithm that allows humans to derive novel ontologies (conceptual schemes). Defined in a more fine-grained manner, the function of that algorithm is “deriving a set of assumptions using which a domain of reality could be decomposed into subdomains that could be studied separately”.
I point out the similarity of this definition to John Wentworth’s operationalization of natural abstractions, from which I build the formal model.
From this foundation, I discuss the discipline of philosophy more broadly. I point out instances where humans seem to employ the “algorithm of philosophical reasoning”, but which don’t fall under the standard definition of “philosophy”. In particular, I discuss the category of research tasks varyingly called “qualitative” or “non-paradigmatic” research, arguing that the core cognitive processes underlying them are implemented using “philosophical reasoning” as well.
Counterweighting that, I define philosophy-as-a-discipline as a special case of such research. While “qualitative research” within a specific field of study focuses on decomposing the domain of reality within that field’s remit, “philosophy” focuses on decomposing reality-as-a-whole (which, in turn, produces the previously mentioned “specific fields of study”).
Separately, I operationalize wisdom as meta-level cognitive heuristics that take object-level heuristics for planning/inference as inputs, and output predictions about the real-world consequences of an agent which makes use of said object-level heuristics. I provide a framework of agency in which that is well-specified as “inversions of inversions of environmental causality”.
I close things off with a discussion of whether “human-level” and “superhuman” AIs would be wise/philosophical (arguing yes), and what options my frameworks offer regarding scaling up or automating both types of reasoning.
1. Philosophical Reasoning
One way to define philosophy is “the study of confusing questions”. Typical philosophical reasoning happens when you notice that you have some intuitions or nagging questions about a domain of reality which hasn’t already been transformed into a formal field of study, and you follow them, attempting to gain clarity. If successful, this often results in the creation of a new field of study focused solely on that domain, and the relevant inquiries stop being part of philosophy.
Notable examples include:
- Physics, which started as “natural philosophy”.
- Chemistry, which was closely related to a much more philosophical “alchemy”.
- Economics, rooted in moral philosophy.
- Psychology, from philosophy of mind.
Another field that serves as a good example is agent foundations1, for those readers familiar with it.
One notable feature of this process is that the new fields, once operationalized, become decoupled from the rest of reality by certain assumptions. A focus on laws that apply to all matter (physics); or on physical interactions of specific high-level structures that are only possible under non-extreme temperatures and otherwise-constrained environmental conditions (chemistry); or on the behavior of human minds; and so on.
This isolation allows each of these disciplines to be studied separately. A physicist doesn’t need training in psychology or economics, and vice versa. By the same token, a physicist mostly doesn’t need to engage in interdisciplinary philosophical ponderings: the philosophical work that created the field has already laid down the conceptual boundaries beyond which physicists mostly don’t need to go.
The core feature underlying this overarching process of philosophy is the aforementioned “philosophical reasoning”: the cognitive algorithms that implement our ability to generate valid decompositions of systems or datasets. Formalizing these algorithms should serve as the starting point for operationalizing philosophy in a more general sense.
1A. What Is an Ontology?
In the context of this text, an “ontology” is a decomposition of some domain of study into a set of higher-level concepts, which characterize the domain in a way that is compact, comprehensive, and could be used to produce models that have high predictive accuracy.
In more detail:
- “Compactness”: The ontology has fewer “moving parts” (concepts, variables) than a full description of the corresponding domain. Using models based on the ontology for making predictions requires a dramatically lower amount of computational or cognitive resources, compared to a “fully detailed” model.
- “Accuracy”: An ontology-based model produces predictions about the domain that are fairly accurate at a high level, or have a good upper bound on error.
- “Comprehensive”: The ontology is valid for all or almost all systems that we would classify as belonging to the domain in question, and characterizes them according to a known, finite family of concepts.
Chemistry talks about atoms, molecules, and reactions between them; economics talks about agents, utility functions, resources, and trades; psychology recognizes minds, beliefs, memories, and emotions. An ontology answers the question of what you study when you study some domain, characterizes the joints along which the domain can be carved and which questions about it are meaningful to focus on. (In this sense, it’s similar to the philosophical notion of a “conceptual scheme”, although I don’t think it’s an exact match.)
Under this view, deriving the “highest-level ontology” – the ontology for the-reality-as-a-whole – decomposes reality into a set of concepts such as “physics”, “chemistry”, or “psychology”. These concepts explicitly classify which parts of reality could be viewed as their instances, thereby decomposing reality into domains that could be studied separately (and from which the disciplines of physics, chemistry, and psychology could spring).
By contrast, on a lower level, arriving at the ontology of some specific field of study allows you to decompose it into specific sub-fields. These subfields can, likewise, be studied mostly separately. (The study of gasses vs. quantum particles, or inorganic vs. organic compounds, or emotional responses vs. memory formation.)
One specific consequence of the above desiderata is that good ontologies commute.
That is, suppose you have some already-defined domain of reality, such as “chemistry”. You’d like to further decompose it into sub-domains. You take some system from this domain, such as a specific chemical process, and derive a prospective ontology for it. The ontology purports to decompose the system into a set of high-level variables plus compactly specified interactions between them, producing a predictive model of it.
If you then take a different system from the same domain, the same ontology should work for it. If you talked about “spirits” and “ether” in the first case, but you need to discuss “molecules” and “chemical reactions” to model the second one, then the spirits-and-ether ontology doesn’t suffice to capture the entire domain. And if there are no extant domains of reality which are well-characterized by your ontology – if the ontology of spirits and ether was derived by “overfitting” to the behavior of the first system, and it fails to robustly generalize to other examples – then this ontology is a bad one.
The go-to historical example comes from the field of chemistry: the phlogiston theory. The theory aimed to explain combustion, modeling it as the release of some substance called “phlogiston”. However, the theory’s explanations for different experiments implied contradictory underlying dynamics. In some materials, phlogiston was supposed to have positive mass (and its release decreased the materials’ weight); in others, negative mass (in metals, to explain why they gained weight after being burned). The explanations for its interactions with air were likewise ad-hoc, often invented post factum to rationalize an experimental result, and essentially never to predict it. That is, they were overfit.
Another field worth examining here is agent foundations. The process of deriving a suitable ontology for it hasn’t yet finished. Accordingly, it is plagued by questions of what concepts / features it should be founded upon. Should we define agency from idealized utility-maximizers, or should we define it structurally? Is consequentialism-like goal-directed behavior even the right thing to focus on, when studying real-world agent-like systems? What formal definition do the “values” of realistic agents have?
In other words: what is the set of variables which serve to compactly and comprehensively characterize and model any system we intuitively associate with “agents”, the same way chemistry can characterize any chemical interaction in terms of molecules and atoms?
Another telling example is mechanistic interpretability. Despite being a very concrete and empirics-based field of study, it likewise involves attempts to derive a novel ontology for studying neural networks. Can individual neurons be studied separately? The evidence suggests otherwise. If not, what are the basic “building blocks” of neural networks? We can always decompose a given set of activations into sparse components, but what decompositions would be robust, i. e., applicable to all forward passes of a given ML model? (Sparse autoencoders represent some progress along this line of inquiry.)
At this point, it should be noted that the process of deriving ontologies, which was previously linked to “philosophical reasoning”, seems to show up in contexts that are far from the traditional ideas of what “philosophy” is. I argue that this is not an error: we are attempting to investigate a cognitive algorithm that is core to philosophy-as-a-discipline, yet it’s not a given that this algorithm would show up only in the context of philosophy. (An extended discussion of this point follows in 1C and 1E.)
To summarize: Philosophical reasoning involves focusing on some domain of reality2 to derive an ontology for it. That ontology could then be used to produce a “high-level summary” of any system from the domain, in terms of specific high-level variables and compactly specifiable interactions between them. This, in turn, allows to decompose this domain into further sub-domains.
1B. Tentative Formalization
Put this way, the definition could be linked to John Wentworth’s definition of natural abstractions.
The Natural Abstraction Hypothesis states that the real-world data are distributed such that, for any set of “low-level” variables L representing some specific system or set of systems, we can derive the (set of) high-level variable(s) H, such that they would serve as “natural latents” for L. That is: conditional on the high-level variables H, the low-level variables L would become (approximately) independent3:
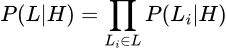
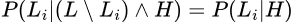
(Where “\” denotes set subtraction, meaning L \ L_i is the set of all L_k except L_i.)
There are two valid ways to interpret L and H.
- The “bottom-up” interpretation: L_i could be different parts of a specific complex system, such as small fragments of a spinning gear. H would then correspond to a set of high-level properties of the gear, such as its rotation speed, the mechanical and molecular properties of its material, and so on. Conditional on H, the individual L_i become independent: once we’ve accounted for the shared material, for example, the only material properties by which they vary are e. g. small molecular defects, individual to each patch.
- The “top-down” interpretation: L_i could be different examples of systems belonging to some reference class of systems, such as individual examples of trees. H would then correspond to the general “tree” abstraction, capturing the (distribution over the) shapes of trees, the materials they tend to be made of, and so on. Conditional on H, the individual L_i become independent: the “leftover” variance are various contingent details such as “how many leaves this particular tree happens to have”.
Per the hypothesis, the high-level variables H would tend to correspond to intuitive human abstractions. In addition, they would be “in the territory” and convergent – in the sense that any efficient agent (or agent-like system) that wants to model some chunk of the world would arrive at approximately the same abstractions for this chunk, regardless of the agent’s goals and quirks of its architecture. What information is shared between individual fragments of a gear, or different examples of trees, is some ground-truth fact about the systems in question, rather than something subject to the agent’s choice.4
The Universality Hypothesis in machine-learning interpretability is a well-supported empirical complement of the NAH. While it doesn’t shed much light on what exact mathematical framework for abstractions we should use, it supplies strong evidence in favor of the NAH’s basic premise: that there’s some notion of abstraction which is convergently learned by agents and agent-like systems.
A natural question, in this formalism, is how to pick the initial set of low-level variables L for the ontology of which we’d be searching: how we know to draw the boundary around the gear, how we know to put only examples of trees into the set L. That question is currently open, although one simple way to handle it might be to simply search for a set such that it’d have a nontrivial natural latent H.
The NAH framework captures the analysis in the preceding sections well. H constitutes the ontology of L, creating conditional independence between the individual variables. Once H is derived, we can study each of L_i separately. (More specifically, we’d be studying L_i conditioned on H: the individual properties of a specific tree in the context of it being a tree; the properties of a physical system in the context of viewing it as a physical system.)
If the disagreement over the shape of H exists – if researchers or philosophers are yet to converge to the same H – that’s a sign that no proposed H is correct, that it fails to robustly induce independence between L_i. (Psychology is an illustrative example here: there are many extant ontologies purporting to characterize the human mind. But while most of them explain some phenomena, none of them explain everything, which leads to different specialists favoring different ontologies – and which is evidence that the correct framework is yet to be found.)
This definition could be applied iteratively: an ontology H would usually consist of a set of variables as well, and there could be a set of even-higher-level variables inducing independence between them. We could move from the description of reality in terms of “all elementary particles in existence” to “all atoms in existence”, and then, for example, to “all cells”, to “all organisms”, to “all species”. Or: “all humans” to “all cities” to “all countries”. Or: starting from a representation of a book in terms of individual sentences, we can compress it to the summary of its plot and themes; starting from the plots and themes of a set of books, we can derive common literary genres. Or: starting from a set of sensory experiences, we can discover some commonalities between these experiences, and conclude that there is some latent “object” depicted in all of them (such as compressing the visual experiences of seeing a tree from multiple angles into a “tree” abstraction). And so on.
In this formalism, we have two notable operations:
- Deriving H given some L.
- Given some L,H, and the relationship P(L | H), propagating some target state “up” or “down” the hierarchy of abstractions.
- That is, if H = H*, what’s P(L | H = H*)? Given some high-level state (macrostate), what’s the (distribution over) low-level states (microstates)?
- On the flip side, if L = L*, what’s P(H | L = L*)? Given some microstate, what macrostate does it correspond to?
It might be helpful to think of P(L | H) and P(H | L) as defining functions for abstracting down H → L and abstracting up L → H, respectively, rather than as a probability distribution. Going forward, I will be using this convention.
I would argue that (2) represents the kinds of thinking, including highly intelligent and sophisticated thinking, which do not correspond to philosophical reasoning. In that case, we already have H → L pre-computed, the ontology defined. The operations involved in propagating the state up/down might be rather complex, but they’re ultimately “closed-form” in a certain sense.
Some prospective examples:
- Tracking the consequences of local political developments on the global economy (going “up”), or on the experiences of individual people (going “down”).
- Evaluating the geopolitical impact of a politician ingesting a specific poisonous substance at a specific time (going “up”).
- Modeling the global consequences of an asteroid impact while taking into account orbital dynamics, weather patterns, and chemical reactions (going “down” to physical details, then back “up”).
- Translating a high-level project specification to build a nuclear reactor into specific instructions to be carried out by manufacturers (“down”).
- Estimating the consequences of a specific fault in the reactor’s design on global policies towards nuclear power (“up”).
As per the examples, this kind of thinking very much encompasses some domains of research and engineering.
(1), on the other hand, potentially represents philosophical reasoning. The question is: what specific cognitive algorithms are involved in that reasoning?
Intuitively, some sort of “babble-and-prune” brute-force approach seems to be at play. We need to semi-randomly test various possible decompositions, until ultimately arriving at one that is actually robust. Another feature is that this sort of thinking requires a wealth of concrete examples, a “training set” we have to study to derive the right abstractions. (Which makes sense: we need a representative sample of the set of random variables L in order to derive approximate conditional-independence relations between them.)
But given that, empirically, the problem of philosophy is computationally tractable at all, it would seem that some heuristics are at play here as well. Whatever algorithms underlie philosophical reasoning, they’re able to narrow down the hypothesis space of ontologies that we have to consider.
Another relevant intuition: from a computational-complexity perspective, the philosophical reasoning of (1), in general, seems to be more demanding than the more formal non-philosophical thinking of (2). Philosophical reasoning seems to involve some iterative search-like procedures, whereas the “non-philosophical” thinking of (2) involves only “simpler” closed-form deterministic functions.
This fits with the empirical evidence: deriving a new useful model for representing some domain of reality is usually a task for entire fields of science, whereas applying a model is something any individual competent researcher or engineer is capable of.
1C. Qualitative Research
Suppose that the core cognitive processes underlying philosophy are indeed about deriving novel ontologies. Is the converse true: all situations in which we’re deriving some novel ontology are “philosophy-like” undertakings, in some important sense?
I would suggest yes.
Let’s consider the mechanistic-interpretability example from 1A. Mechanistic interpretability is a very concrete, down-to-earth field of study, with tight empirical-testing loops. Nevertheless, things like the Universality Hypothesis, and speculations that the computations in neural networks could be decomposed into “computational circuits”, certainly have a philosophical flavor to them – even if the relevant reasoning happens far outside the field of academic philosophy.
Chris Olah, a prominent ML interpretability researcher, characterizes this as “qualitative research”. He points out that one of the telltale signs that this type of research is proceeding productively is finding surprising structure in your empirical results. In other words: finding some way to look at the data which hints at the underlying ontology.
Another common term for this type of research is “pre-paradigmatic” research. The field of agent foundations, for example, is often called “pre-paradigmatic” in the sense that within its context, we don’t know how to correctly phrase even the questions we want answered, nor the definitions of the basic features we want to focus on.
Such research processes are common even in domains that have long been decoupled from philosophy, such as physics. Various attempts to derive the Theory of Everything often involve grappling with very philosophy-like questions regarding the ontology of a physical universe consistent with all our experimental results (e. g., string theory). Different interpretations of quantum mechanics is an even more obvious example.
Thomas Kuhn’s The Structure of Scientific Revolutions naturally deserves a mention here. His decomposition of scientific research into “paradigm shifts” and “normal science” would correspond to the split between (1) and (2) types of reasoning as outlined in the previous section. The research that fuels paradigm shifts would be of the “qualitative”, non-paradigmatic, ontology-discovering type.
Things similar to qualitative/non-paradigmatic research also appear in the world of business. Peter Thiel’s characterization of startups as engaging in “zero to one” creation of qualitatively new markets or goods would seem to correspond to deriving some novel business frameworks, i. e., ontologies, and succeeding by their terms. (“Standard”, non-startup businesses, in this framework’s view, rely on more “formulaic” practices – i. e., on making use of already pre-computed H → L. Consider opening a new steel mill, which would produce well-known products catering to well-known customers, vs. betting on a specific AI R&D paradigm, whose exact place in the market is impossible to predict even if it succeeds.)
Nevertheless, intuitively, there still seems to be some important difference between these “thin slices” of philosophical reasoning scattered across more concrete fields, and “pure” philosophy.
Before diving into this, a short digression:
1D. Qualitative Discoveries Are Often Counterfactual
Since non-paradigmatic research seems more computationally demanding, requiring a greater amount of expertise than in-paradigm reasoning, its results are often highly counterfactual. While more well-operationalized frontier discoveries are often made by many people near-simultaneously, highly qualitative discoveries could often be attributed to a select few people.
As a relatively practical example, Shannon’s information theory plausibly counts. The discussion through the link also offers some additional prospective examples.
From the perspective of the “zero-to-one startups are founded on novel philosophical reasoning” idea, this view is also supported. If a novel startup fails due to some organizational issues before proving the profitability of its business plan, it’s not at all certain that it would be quickly replaced by someone trying the same idea, even if its plan were solid. Failures of the Efficient Market Hypothesis are common in this area.
1E. What Is “Philosophy” As a Discipline?
Suppose that the low-level system L represents some practical problem we study. A neural network that we have to interpret, or the readings yielded by a particle accelerator which narrow down the fundamental physical laws, or the behavior of some foreign culture that we want to trade with. Deriving the ontology H would be an instance of non-paradigmatic research, i. e., philosophical reasoning. But once H is derived, it would be relatively easily put to use solving practical problems. The relationship H → L, once nailed down, would quickly be handed off to engineers or businessmen, who could start employing it to optimize the natural world.
As an example, consider anthropics, an emerging field studying anthropic principles and extended reasoning similar to the doomsday argument.5 Anthropics doesn’t study a concrete practical problem. It’s a very high-level discipline, more or less abstracting over the-world-as-a-whole (or our experiences of it). Finding a proper formalization of anthropics, which satisfactorily handles all edge cases, would result in advancement in decision theory and probability theory. But there are no immediate practical applications.
They likely do exist. But you’d need to propagate the results farther down the hierarchy of abstractions, moving through these theories down to specific subfields and then to specific concrete applications. None of the needed H → L pathways are derived, there’s a lot of multi-level philosophical work to be done. And there’s always the possibility that it would yield no meaningful results, or end up as a very circuitous way to justify common intuitions.
The philosophy of mind could serve as a more traditional example. Branches of it are focused on investigating the nature of consciousness and qualia. Similarly, it’s a very “high-level” direction of study, and the success of its efforts would have significant implications for numerous other disciplines. But it’s not known what, if any, practical consequences of such a success would be.
Those features, I think, characterize “philosophy” as a separate discipline. Philosophy (1) involves attempts to derive wholly new multi-level disciplines, starting from very-high-level reasoning about the-world-as-a-whole (or, at least, drawing on several disciplines at once), and (2) it only cashes out in practical implementations after several iterations of concretization.
In other words, philosophy is the continuing effort to derive the complete highest-level ontology of our experiences/our world.
1F. On Ethics
An important branch of philosophy which hasn’t been discussed so far is moral philosophy. The previously outlined ideas generalize to it in a mostly straightforward manner, though with a specific “pre-processing” twist.
This is necessarily going to be a very compressed summary. For proper treatment of the question, I recommend Steven Byrnes’ series on the human brain and valence signals, or my (admittedly fairly outdated) essay on value formation.
To start off, let’s assume that the historical starting point of moral philosophy are human moral intuitions and feelings. Which actions, goals, or people “feel like” good or bad things, what seems just or unfair, and so on. From this starting point, people developed the notions of morality and ethics, ethical systems, social norms, laws, and explicit value systems and ideologies.
The process of moral philosophy can then be characterized as follows:
As a premise, human brains contain learning algorithms plus a suite of reinforcement-learning training signals.
In the course of life, and especially in childhood, a human learns a vast repository of value functions. These functions take sensory perceptions and thoughts as inputs, and output “valence signals” in the form of real numbers. The valence assigned to a thought is based on learned predictive heuristics about whether a given type of thought has historically led to positive or negative reward (as historically scored by innate reinforcement-signal functions).
The valences are perceived by human minds as a type of sensory input. In particular, a subset of learned value functions could be characterized as “moral” value functions, and their outputs are perceived by humans as the aforementioned feelings of “good”, “bad”, “justice”, and so on.
Importantly, the learned value functions aren’t part of a human’s learned world-model (explicit knowledge). As the result, their explicit definitions aren’t immediately available to our conscious inspection. They’re “black boxes”: we only perceive their outputs.
One aspect of moral philosophy, thus, is to recover these explicit definitions: what value functions you’ve learned and what abstract concepts they’re “attached to”. (For example: does “stealing” feel bad because you think it’s unfair, or because you fear being caught? You can investigate this by, for example, imagining situations in which you manage to steal something in circumstances where you feel confident you won’t get caught. This would allow you to remove the influence of “fear of punishment”, and thereby determine whether you have a fairness-related value function.)
That is a type of philosophical reasoning: an attempt to “abstract up” from a set of sensory experiences of a specific modality, to a function defined over high-level concepts. (Similar to recovering a “tree” abstraction by abstracting up from a set of observations of a tree from multiple angles.)
Building on that, once a human has recovered (some of) their learned value functions, they can keep abstracting up in the manner described in the preceding text. For example, a set of values like “I don’t like to steal”, “I don’t like to kill”, “I don’t like making people cry” could be abstracted up to “I don’t want to hurt people”.
Building up further, we can abstract over the set of value systems recovered by different people, and derive e. g. the values of a society…
… and, ultimately, “human values” as a whole.
Admittedly, there are some obvious complications here, such as the need to handle value conflicts / inconsistent values, and sometimes making the deliberate choice to discard various data points in the process of computing higher-level values (often on the basis of meta-value functions). For example, not accounting for violent criminals when computing the values a society wants to strive for, or discarding violent impulses when making decisions about what kind of person you want to be.
In other words: when it comes to values, there is an “ought” sneaking into the process of abstracting-up, whereas in all other cases, it’s a purely “is”-fueled process.
But the “ought” side of it can be viewed as simply making decisions about what data to put in the L set, which we’d then abstract over in the usual, purely descriptive fashion.
From this, I conclude that the basic algorithmic machinery, especially one underlying the philosophical (rather than the political) aspects of ethical reasoning, is still the same as with all other kinds of philosophical reasoning.
1G. Why Do “Solved” Philosophical Problems Stop Being Philosophy?
As per the formulations above:
- The endeavor we intuitively view as “philosophy” is a specific subset of general philosophical reasoning/non-paradigmatic research. It involves thinking about the world in a very general sense, without the philosophical assumptions that decompose it into separate domains of study.
- “Solving” a philosophical problem involves deriving an ontology/paradigm for some domain of reality, which allows to decouple that domain from the rest of the world and study it mostly separately.
Put like this, it seems natural that philosophical successes move domains outside the remit of philosophy. Once a domain has been delineated, thinking about it by definition no longer requires the interdisciplinary reasoning characteristic of philosophy-as-a-discipline. Philosophical reasoning seeks to render itself unnecessary.
(As per the previous sections, working in the domains thus delineated could still involve qualitative research, i. e., philosophical reasoning. But not the specific subtype of philosophical reasoning characteristic of philosophy-as-a-discipline, involving reasoning about the-world-as-a-whole.)
In turn, this separation allows specialization. Newcomers could focus their research and education on the delineated domain, without having to become interdisciplinary specialists. This means a larger quantity of people could devote themselves to it, leading to faster progress.
That dynamic is also bolstered by greater funding. Once the practical implications of a domain become clear, more money pours into it, attracting even more people.
As a very concrete example, we can consider the path-expansion trick in mechanistic interpretability. Figuring out how to mathematically decompose a one-layer transformer into the OV and QK circuits requires high-level reasoning about transformer architecture, and arriving at the very idea of trying to do so requires philosophy-like thinking (to even think to ask, “how can we decompose a ML model into separate building blocks?”). But once this decomposition has been determined, each of these circuits could be studied separately, including by people who don’t have the expertise to derive the decomposition from scratch.
Solving a philosophical problem, then, often allows to greatly upscale the amount of work done in the relevant domain of reality. Sometimes, that quickly turns it into an industry.
2. Wisdom
Let’s consider a wide variety of “wise” behavior or thinking.
- Taking into account “second-order” effects of your actions.
- Example: The “transplant problem”, which examines whether you should cut up a healthy non-consenting person for organs if that would let you save five people whose organs are failing.
- “Smart-but-unwise” reasoning does some math and bites the bullet.
- “Wise” reasoning points out that if medical professionals engaged in this sort of behavior at scale, people would stop seeking medical attention out of fear/distrust, leading to more suffering in the long run.
- Taking into account your history with specific decisions, and updating accordingly.
- Example 1:
- Suppose you have an early appointment tomorrow, but you’re staying up late, engrossed in a book. Reasoning that you will read “just one more chapter” might seem sensible: going to sleep at 01:00 AM vs. 01:15 AM would likely have no significant impact on your future wakefulness.
- However, suppose that you end up making this decision repeatedly, until it’s 6:40 AM and you have barely any time left for sleep at all.
- Now suppose that a week later, you’re in a similar situation: it’s 01:00 AM, you’ll need to wake up early, and you’re reading a book.
- “Smart-but-unwise” reasoning would repeat your previous mistake: it’d argue that going to sleep fifteen minutes later is fine.
- “Wise” reasoning would update on the previous mistake, know not to trust its object-level estimates, and go to sleep immediately.
- Example 2:
- Suppose that someone did something very offensive to you. In the moment, you infer that this means they hate you, and update your beliefs accordingly.
- Later, it turns out they weren’t aware that their actions upset you, and they apologize and never repeat that error.
- Next time someone offends you, you may consider it “wise” not to trust your instinctive interpretation completely, and at least consider alternate explanations.
- Example 1:
- Taking into account the impact of the fact that you’re the sort of person to make a specific decision in a specific situation.
- Example 1:
- Suppose that a staunch pacifist is offered a deal: they take a pill that would decrease their willingness to kill by 1%, and in exchange, they get 1 million dollars. In addition, they could take that deal multiple times, getting an additional 1 million dollars each time, and raising their willingness to kill by 1% each time.
- A “smart-but-unwise” pacifist reasons that they’d still be unwilling to kill even if they became, say, 10% more willing to, and that they could spend the 10 million dollars on charitable causes, so they decide to take the deal 10 times.
- A “wise” pacifist might consider the fact that, if they take the deal 10 times, the one making the decision on whether to continue would be a 10%-more-willing-to-kill version of them. That version might consider it acceptable to go up to 20%; a 20% version might consider 40% acceptable, and so on until 100%.
- Example 2: Blackmailability.
- Suppose that we have two people, Alice and Carol. Alice is known as a reasonable, measured person who makes decisions carefully, minimizing risk. Carol is known as a very temperamental person who becomes enraged and irrationally violent at the slightest offense.
- Suppose that you’re a criminal who wants to blackmail someone. If you’re choosing between Alice and Carol, Alice is a much better target: if you threaten to ruin her life if she doesn’t pay you $10,000, she will tally up the costs and concede. Carol, on the other hand, might see red and attempt to murder you, even if that seals her own fate.
- Alice is “smart-but-unwise”. Carol, as stated, isn’t exactly “wise”. But she becomes “wise” under one provision: if she committed to her “irrational” decision policy as a result of rational reasoning about what would make her an unappealing blackmail target. After all, in this setup, she’s certainly the one who ends up better off than Alice!
- (Functional Decision Theories attempt to formalize this type of reasoning, providing a framework within which it’s strictly rational.)
- Example 1:
- Erring on the side of deferring to common sense in situations where you think you see an unexploited opportunity.
- Example 1: Engaging in immoral behavior based on some highly convoluted consequentialist reasoning vs. avoiding deontology violations. See this article for an extended discussion of the topic.
- This is similar to (1), but in this case, you don’t need to reason through the nth-order effects “manually”. You know that deferring to common sense is usually wise, even if you don’t know why the common sense is the way it is.
- It’s also fairly similar to the first example in (3), but the setup here is much more realistic.
- Example 2: Trying to estimate the price of a stock “from scratch”, vs. “zeroing out”, i. e., taking the market value as the baseline and then updating it up/down based on whatever special information you have.
- Example 3: Getting “bad vibes” from a specific workplace environment or group of people, and dismissing these feelings as irrational (“smart-but-unwise”), vs. trying to investigate in-depth what caused them (“wise”). (And discovering, for example, that they were caused by some subtle symptoms of unhealthy social dynamics, which the global culture taught you to spot, but didn’t explain the meaning of.)
- Example 1: Engaging in immoral behavior based on some highly convoluted consequentialist reasoning vs. avoiding deontology violations. See this article for an extended discussion of the topic.
- Taking the “outside view” into account (in some situations in which it’s appropriate).
- Example: Being completely convinced of your revolutionary new physics theory or business plan, vs. being excited by it, but skeptical on the meta level, on the reasoning that there’s a decent chance your object-level derivations/plans contain an error.
Summing up: All examples of “wise” behavior here involve (1) generating some candidate plan or inference, which seems reliable or correct while you’re evaluating it using your object-level heuristics, then (2) looking at the appropriate reference class of these plans/inferences, and finally (3) predicting what the actual consequences/accuracy would be using your meta-level heuristics. (“What if everyone acted this way?”, “what happened the previous times I acted/thought this way?”, “what would happen if it were commonly known I’d act this way?”, “if this is so easy, why haven’t others done this already?”, and so on.)
Naturally, it could go even higher. First-order “wise” reasoning might be unwise from a meta-meta-level perspective, and so on.
(For example, “outside-view” reasoning is often overused, and an even more wise kind of reasoning recognizes when inside-view considerations legitimately prevail over outside-view ones. Similarly, the heuristic of “the market is efficient and I can’t beat it” is usually wise, wiser than “my uncle beat the market this one time, which means I can too if I’m clever enough!”, but sometimes there are legitimate market failures.6)
In other words: “wise” thinking seems to be a two-step process, where you first generate a conclusion that you expect to be accurate, then “go meta”, and predict what would be the actual accuracy rate of a decision procedure that predicts this sort of conclusion to be accurate.
2A. Background Formalisms
To start off, I will need to introduce a toy model of agency. Bear with me.
First: How can we model the inferences from the inputs to an agent’s decisions?
Photons hit our eyes. Our brains draw an image aggregating the information each photon gives us. We interpret this image, decomposing it into objects, and inferring which latent-variable object is responsible for generating which part of the image. Then we wonder further: what process generated each of these objects? For example, if one of the “objects” is a news article, what is it talking about? Who wrote it? What events is it trying to capture? What set these events into motion? And so on.
In diagram format, we’re doing something like this:

Blue are ground-truth variables, gray is the “Cartesian boundary” of our mind from which we read off observations, purple are nodes in our world-model, each of which can be mapped to a ground-truth variable.
We take in observations, infer what latent variables generated them, then infer what generated those variables, and so on. We go backwards: from effects to causes, iteratively. The Cartesian boundary of our input can be viewed as a “mirror” of a sort, reflecting the Past.
It’s a bit messier in practice, of course. There are shortcuts, ways to map immediate observations to far-off states. But the general idea mostly checks out – especially given that these “shortcuts” probably still implicitly route through all the intermediate variables, just without explicitly computing them. (You can map a news article to the events it’s describing without explicitly modeling the intermediary steps of witnesses, journalists, editing, and publishing. But your mapping function is still implicitly shaped by the known quirks of those intermediaries.)
Second: Let’s now consider the “output side” of an agent. I. e., what happens when we’re planning to achieve some goal, in a consequentialist-like manner.
We envision the target state. What we want to achieve, how the world would look like. Then we ask ourselves: what would cause this? What forces could influence the outcome to align with our desires? And then: how do we control these forces? What actions would we need to take in order to make the network of causes and effects steer the world towards our desires?
In diagram format, we’re doing something like this:
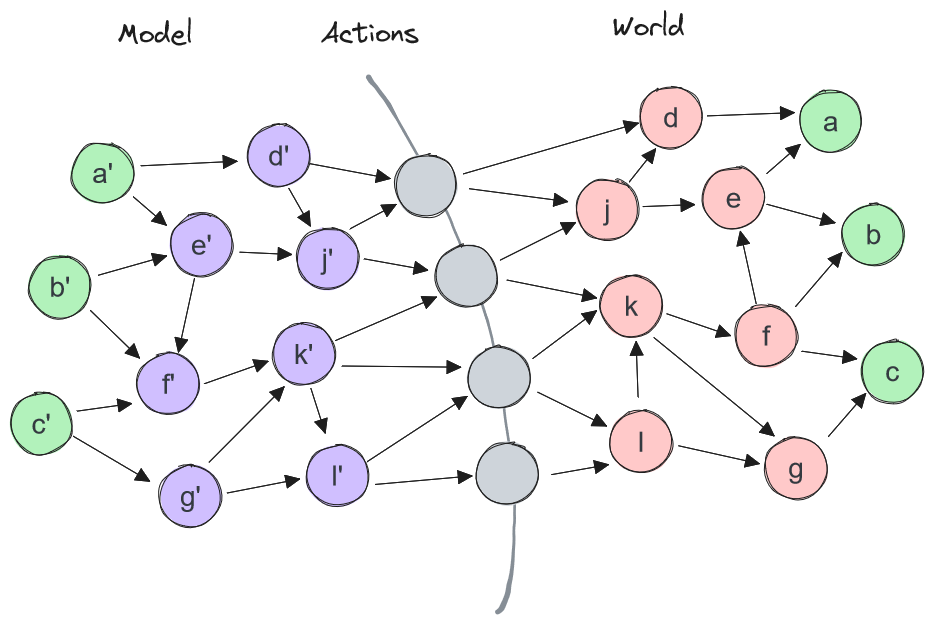
Green are goals, purple are intermediary variables we compute, gray is the Cartesian boundary of our actions, red are ground-truth variables through which we influence our target variables.
We start from our goals, infer what latent variables control their state in the real world, then infer what controls those latent variables, and so on. We go backwards: from effects to causes, iteratively, until getting to our own actions. The Cartesian boundary of our output can be viewed as a “mirror” of a sort, reflecting the Future.
It’s a bit messier in practice, of course. There are shortcuts, ways to map far-off goals to immediate actions. But the general idea mostly checks out – especially given that these heuristics probably still implicitly route through all the intermediate variables, just without explicitly computing them. (“Acquire resources” is a good heuristical starting point for basically any plan. But what counts as resources is something you had to figure out in the first place by mapping from “what lets me achieve goals in this environment?”.)
And indeed, that side of this formulation isn’t novel. From this post by Scott Garrabrant, an agent-foundations researcher:
Time is also crucial for thinking about agency. My best short-phrase definition of agency is that agency is time travel. An agent is a mechanism through which the future is able to affect the past. An agent models the future consequences of its actions, and chooses actions on the basis of those consequences. In that sense, the consequence causes the action, in spite of the fact that the action comes earlier in the standard physical sense.
Let’s now put both sides together. An idealized, compute-unbounded “agent” could be laid out in this manner:

It reflects the past at the input side, and reflects the future at the output side. In the middle, there’s some “glue”/”bridge” connecting the past and the future by a forwards-simulation. During that, the agent “catches up to the present”: figures out what will happen while it’s figuring out what to do.
If we consider the relation between utility functions and probability distributions, it gets even more formally literal. An utility function over X could be viewed as a target probability distribution over X, and maximizing expected utility is equivalent to minimizing cross-entropy between this target distribution and the real distribution.
That brings the “planning” process in alignment with the “inference” process: both are about propagating target distributions “backwards” in time through the network of causality.
2B. Tentative Formalization
Let’s consider what definition “wisdom” would have, in this framework.
All “object-level” cognitive heuristics here have a form of Y → X, where Y is some environmental variable, and X are the variables that cause Y. I. e., every cognitive heuristic Y → X can be characterized as an inversion of some environmental dynamic X → Y.
“Wisdom”, in this formulation, seems to correspond to inversions of inversions. Its form is
(Y → X) → Y.
It takes in some object-level inversion – an object-level cognitive heuristic – and predicts things about the performance of a cognitive policy that uses this heuristic.
Examining this definition from both ends:
- If we’re considering an object-level output-side heuristic E → A, which maps environmental variables E to actions A that need to be executed in order to set E to specific values – i. e., a “planning” heuristic – the corresponding “wisdom” heuristic (E → A) → E tells us what object-level consequences E the reasoning of this type actually results in.
- If we’re considering an object-level input-side heuristic O → E mapping observations O to their environmental causes E – i. e., an “inference” heuristic – the corresponding “wisdom” heuristic (O → E) → O tells us what we’d actually expect to see going forward, and whether the new observations would diverge from our object-level inferences. (I. e., whether we expect that the person who offended us would actually start acting like they hate us, going forward.)
Admittedly, some of these speculations are fairly shaky. The “input-side” model of wisdom, in particular, seems off to me. Nevertheless, I think this toy formalism does make some intuitive sense.
It’s also clear, from this perspective, why “wisdom” is inherently more complicated / hard-to-compute than “normal” reasoning: it explicitly iterates on object-level reasoning.
2C. Crystallized Wisdom
In humans, cognitive heuristics are often not part of explicit knowledge, but are instead stored as learned instincts, patterns of behavior, or emotional responses – or “shards”, in the parlance of one popular framework.
Since wisdom is a subset of cognitive heuristics, that applies to it as well. “Wise” heuristics are often part of “common sense”, tacit knowledge, cultural norms, and hard-to-articulate intuitions and hunches. In some circumstances, they’re stored in a format that doesn’t refer to the initial object-level heuristic at all! Heuristics such as “don’t violate deontology” don’t activate only in response to object-level criminal plans.
(Essentially, wisdom is conceptually/logically downstream of object-level heuristics, but not necessarily cognitively downstream, in the sense of moment-to-moment perceived mental experiences.)
Indeed, wisdom heuristics, by virtue of being more computationally demanding, are likely to be stored in an “implicit” form more often than “object-level” heuristics. Deriving them explicitly often requires looking at “global” properties of the environment or your history in it, considering the whole reference class of the relevant object-level cognitive heuristic. By contrast, object-level heuristics themselves involve a merely “local” inversion of some environmental dynamic.
As the result, “wisdom” usually only accumulates after humanity has engaged with some domain of reality for a while. Similarly, individual people tend to become “wise” only after they personally were submerged in that domain for a while – after they “had some experience” with it.
That said, to the extent that this model of wisdom is correct, wisdom can nevertheless be inferred “manually”, with enough effort. After all, it’s still merely a function of the object-level domain. It could be derived purely from the domain’s object-level model, given enough effort and computational resources, no “practical experience” needed.
3. Would AGIs Pursue Wisdom & Philosophical Competence?
In my view, the answer is a clear “yes”.
To start off, let’s define an “AGI” as “a system which can discover novel abstractions (such as new fields of science) in any environment that has them, and fluently use these abstractions in order to better navigate or optimize its environment in the pursuit of its goals”.
It’s somewhat at odds with the more standard definitions, which tend to characterize AGIs as, for example, “systems that can do most cognitive tasks that a human can”. But I think it captures some intuitions better than the standard definitions. For one, the state-of-the-art LLMs certainly seem to be “capable of doing most cognitive tasks that humans can”, yet most specialists and laymen alike would agree that they are not AGI. Per my definition, it’s because LLMs cannot discover new ontologies: they merely learned vast repositories of abstractions that were pre-computed for them by humans.
As per my arguments, philosophical reasoning is convergent:
- It’s a subset of general non-paradigmatic research…
- … which is the process of deriving new ontologies…
- … which are useful because they allow to decompose the world into domains that can be reasoned about mostly-separately…
- … which is useful because it reduces the computational costs needed for making plans or inferences.
Any efficient bounded agent, thus, would necessarily become a competent philosopher, and it would engage in philosophical reasoning regarding all domains of reality that (directly or indirectly) concern it.
Consider the opposite: “philosophically incompetent” or incapable reasoners. Such reasoners would only be able to make use of pre-computed H → L relations. They would not be able to derive genuinely new abstractions and create new fields. Thus, they wouldn’t classify as “AGI” in the above-defined sense.
They’d be mundane, non-general software tools. They’d still be able to be quite complex and intelligent, in some ways, up to and including being able to write graduate-level essays or even complete formulaic engineering projects. Nevertheless, they’d fall short of the “AGI” bar. (And would likely represent no existential risk on their own, outside cases of misuse by human actors.)
As a specific edge case, we can consider humans who are capable researchers in their domain – including being able to derive novel ontologies – but are still philosophically incompetent in a broad sense. I’d argue that this corresponds to the split between “general” philosophical reasoning, and “philosophy as a discipline” I’ve discussed in 1E. These people likely could be capable philosophers, but simply have no interest in specializing in high-level reasoning about the-world-in-general, nor in exploring its highest-level ontology.
Something similar could happen with AGIs trained/designed a specific way. But in the limit of superintelligence, it seems likely that all generally intelligent minds converge to being philosophically competent.
Wisdom is also convergent. When it comes down to it, wisdom seems to just be an additional trick for making correct plans or inferences. “Smart but unwise” reasoning would correspond to cases in which you’re not skeptical of your own decision-making procedures, are mostly not trying to improve them, and only take immediate/local consequences of your action into account. Inasmuch as AGIs would be capable of long-term planning across many domains, they would strive to be “wise”, in the sense I’ve outlined in this essay.
And those AGIs that would have superhuman general-intelligence capabilities, would be able to derive the “wisdom” heuristics quicker than humans, with little or no practical experience in a domain.
4. Philosophically Incompetent Human Decision-Makers
That said, just because AGIs would be philosophically competent, that doesn’t mean they’d by-default address and fix the philosophical incompetence of the humans who created them. Even if these AGIs would be otherwise aligned to human intentions and inclined to follow human commands.
The main difficulty here is that humans store their values in a decompiled/incomplete format. We don’t have explicit utility functions: our values are a combination of explicit consciously-derived preferences, implicit preferences, emotions, subconscious urges, and so on. (Theoretically, it may be possible to compile all of that into a utility function, but that’s a very open problem.)
As the result, mere intent alignment – designing an AGI which would do what its human operators “genuinely want” it to do, when they give it some command – still leaves a lot of philosophical difficulties and free parameters.
For example, suppose the AGI’s operators, in a moment of excitement after they activate their AGI for the first time, tell it to solve world hunger. What should the AGI do?
- Should it read off the surface-level momentary intent of this command, design some sort of highly nutritious and easy-to-produce food, and distribute it across the planet in the specific way the human is currently imagining this?
- Should it extrapolate the human’s values, and execute the command the way the human would have wanted to execute it if they’d thought about it for a bit, rather than the way they’re envisioning it in the moment?
- (For example, perhaps the image flashing through the human’s mind right now is of helicopters literally dropping crates full of food near famished people, but it’s actually more efficient to do it using airplanes.)
- Should it extrapolate the human’s values a bit, and point out specific issues with this plan that the human might think about later (e. g., that such sudden large-scale activity might provoke rash actions from various geopolitical actors, leading to vast suffering), then give the human a chance to abort?
- Should it extrapolate the human’s values a bit further, and point out issues the human might not have thought of (including teaching the human any novel load-bearing concepts necessary for understanding said potential issues)?
- Should it extrapolate the human’s values a bit further still, and teach them various better cognitive protocols for self-reflection, so that they may better evaluate whether a given plan satisfies their values?
- Should it extrapolate the human’s values far afield, interpret the command as “maximize eudaimonia”, and do that, disregarding the specific rough way of how they gestured at the idea?
- In other words: should it directly optimize for the human’s coherent extrapolated volition (which is something like the ultimate output of abstracting-over-ethics that I’d gestured at in 1F)?
- Should it remind the human that they’d wanted to be careful regarding how they use the AGI, and to clarify whether they actually want to proceed with something so high-impact right now?
- Should it insist that the human is currently too philosophically confused to make such high-impact decisions, and the AGI first needs to teach them a lot of novel concepts, before they can be sure there are no unknown unknowns that’d put their current plans at odds with their extrapolated values?
There are many, many drastically different ways to implement something as seemingly intuitive as “Do What I Mean”. And unless “aligning AIs to human intent” is done in the specific way that puts as much emphasis as possible on philosophical competence, including refusing human commands if the AGI judges them unwise/philosophically incompetent – short of that, even an AGI that is intent-aligned (in some strict technical sense) might lead to existentially catastrophic outcomes, up to and including the possibility of suffering at astronomical scales.
For example, suppose the AGI is designed to act on the surface-level meaning of commands, and it’s told to “earn as much money as possible, by any means necessary”. As I’ve argued in Section 3, it would derive a wise and philosophically competent understanding of what “obeying the surface-level meaning of a human’s command” means, and how to wisely and philosophically competently execute on this specific command. But it would not question the wisdom and philosophical competence of the command from the perspective of a counterfactual wiser human. Why would it, unless specifically designed to?
Another example: If the AGI is “left to its own devices” regarding how to execute on some concrete goal, it’d likely do everything “correctly” regarding certain philosophically-novel-to-us situations, such as the hypothetical possibility of acausal trade with the rest of the multiverse. (If the universal prior is malign, and using it is a bad idea, an actual AGI would just use something else.) However, if the AGI is corrigible, and it explains the situation to a philosophically incompetent human operator before taking any action, the human might incorrectly decide that giving in to acausal blackmail is the correct thing to do, and order the AGI to do so.
On top of that, there’s a certain Catch-22 at play. Convincing the decision-makers or engineers that the AGI must be designed such that it’d only accept commands from wise philosophically competent people already requires some level of philosophical competence on the designers’ part. They’d need to know that there even are philosophical “unknown unknowns” that they must be wary of, and that faithfully interpreting human commands is more complicated than just reading off the human’s intent at the time they give the command.
How to arrive at that state of affairs is an open question.
5. Ecosystem-Building
As argued in 1G, the best way to upscale the process of attaining philosophical competence and teaching it to people would be to move metaphilosophy outside the domain of philosophy. Figure out the ontology suitable for robustly describing any and all kinds of philosophical reasoning, and decouple from the rest of reality.
This would:
- Allow more people to specialize in metaphilosophy, since they’d only need to learn about this specific domain of reality, rather than becoming interdisciplinary experts reasoning about the world at a high level.
- Simplify the transfer of knowledge and the process of training new people. Once we have a solid model of metaphilosophy, that’d give us a ground-truth idea of how to translate philosophical projects into concrete steps of actions (i. e., what the H → L functions are). Those could be more easily taught in a standardized format, allowing at-scale teaching and at-scale delegation of project management.
- Give us the means to measure philosophical successes and failures, and therefore, how to steer philosophical projects and keep them on-track. (Which, again, would allow us to scale the size and number of such projects. How well they perform would become legible, giving us the ability to optimize for that clear metric.)
- Provide legibility in general. Once we have a concrete, convergent idea of what philosophical projects are, how they succeed, and what their benefits are, we’d be able to more easily argue the importance of this agenda to other people and organizations, increasing the agenda’s reach and attracting funding.
Hopefully this essay and the formalisms in it provide the starting point for operationalizing metaphilosophy in a way suitable for scaling it up.
Similar goes for wisdom – although unlike teaching philosophical competence, this area seems less neglected. (Large-scale projects for “raising the sanity waterline” have been attempted in the past, and I think any hypothetical “wisdom-boosting” project would look more or less the same.)
6. Philosophy Automation
In my view, automating philosophical reasoning is an AGI-complete problem. I think that the ability to engage in qualitative/non-paradigmatic research is what defines a mind as generally intelligent.
This is why LLMs, for example, are so persistently bad at it, despite their decent competence in other cognitive areas. I would argue that LLMs contain vast amounts of crystallized heuristics – that is, H → L functions, in this essay’s terminology – yet no ability to derive new ontologies/abstractions H given a low-level system L. Thus, there are no types of philosophical reasoning they’d be good at; no ability to contribute on their own/autonomously.
On top of that, since we ourselves don’t know the ontology of metaphilosophy either, that likely cripples our ability to use AI tools for philosophy in general. The reason is the same as the barrier to scaling up philosophical projects: we don’t know how the domain of metaphilosophy factorizes, which means we don’t know how to competently outsource philosophical projects and sub-projects, how to train AIs specialized in this, and how to measure their successes or failures.
One approach that might work is “cyborgism”, as defined by janus. Essentially, it uses LLMs as a brainstorming tool, allowing to scope out vastly larger regions of concept-space for philosophical insights, with the LLMs’ thought-processes steered by a human. In theory, this gives us the best of both worlds: a human’s philosophy-capable algorithms are enhanced by the vast repository of crystallized H → L and L → H functions contained within the LLM. Janus has been able to generate some coherent-ish philosophical artefacts this way. However, this idea has been around for a while, and so far, I haven’t seen any payoff from it.
Overall, I’m very skeptical that LLMs could be of any help here whatsoever, besides their standard mundane-utility role of teaching people new concepts in a user-tailored format. (Which might be helpful, in fact, but it isn’t the main bottleneck here. As I’ve discussed in Section 5, this sort of at-scale distribution of standardized knowledge only becomes possible after the high-level ontology of what we want to teach is nailed down.)
What does offer some hope for automating philosophy is the research agenda focused on the Natural Abstraction Hypothesis. I’ve discussed it above, and my tentative operationalization of philosophy is based on it. The agenda is focused on finding a formal definition for abstractions (i. e., layers of ontology), and what algorithms could at least assist us with deriving new ones.
Thus, inasmuch as my model of philosophy is right, the NAH agenda is precisely focused on operationalizing philosophical reasoning. John Wentworth additionally discusses some of the NAH’s applications for metaphilosophy here.
Thanks to David Manley, Linh Chi Nguyen, and Bradford Saad for providing extensive helpful critique of an earlier draft, and to John Wentworth for proofreading the final version.
Notes
- A niche field closely tied to AI research, which attempts to formalize the notion of generally intelligent agents capable of pursuing coherent goals across different contexts, domains, and time scales.
- Which was, itself, made independent from the rest of reality by assumptions produced by a higher-level instance of philosophical reasoning.
- The generalization of the framework explicitly able to handle approximation could be found through this link.
- In theory, there might be some free parameters regarding the exact representation an agent would choose, if there are several possible representations with the same size and predictive accuracy. Efforts to show that any two such representations would be importantly isomorphic to each other are ongoing.
- Given that we’re able to make a particular observation, what does that tell us about the structure of reality? For example, the fact that intelligent life exists at all already narrows down what laws of physics our universe must have. We can infer something about them purely from observing our own existence, without actually looking around and directly studying them.
- Eliezer Yudkowsky’s Inadequate Equilibria discusses this topic in great detail.