By Katja Grace, 9 February 2015
A natural approach to informing oneself about when human-level AI will arrive is to check what experts who have already investigated the question say about it. So we made this list of analyses that we could find.
It’s a short list, though the bar for ‘analysis’ was low. Blame for the brevity should probably be divided between our neglect of worthy entries and the world’s neglect of worthy research. Nonetheless we can say interesting things about the list.
About half of the estimates are based on extrapolating hardware, usually to something like ‘human-equivalence’. A stylized estimate along these lines might run as follows:
- Calculate how much computation the brain does.
- Extrapolate the future costs for computing hardware (it goes downward, fast)
- Find the point in the computing hardware cost trajectory where brain-equivalent hardware (1) becomes pretty cheap, for some value of ‘pretty cheap’.
- Guestimate how long software will take once we have enough hardware; add this to the date produced in (3).
- The date produced in (4) is your estimate for human-level AI.
How solid is this kind of estimate? Let us consider it in a bit of detail.
How much computation is a brain worth?
It is not trivial to estimate how much computation a brain does. A basic philosophical problem is that we don’t actually know what the brain is doing much, so it’s not obvious what part of its behavior is contributing to computation in any particular way. For instance (implausibly) if some of the neuron firing was doing computation, and the rest was just keeping the neurons prepared, we wouldn’t know. We don’t know how much detail of the neurons and their contents and surrounds is relevant to the information processing we are interested in.
Moravec (2009) estimates how much computation the brain does by extrapolation from the retina. He estimates how much computing hardware would be needed for a computer to achieve the basic image processing that parts of the retina do, then multiplies this by how much heavier the brain is than parts of the retina. As he admits, this is a coarse estimate. I don’t actually have much idea how accurate you would expect this to be. Some obvious possible sources of inaccuracy are the retina being unrepresentative of the brain (as it appears to be for multiple reasons), the retina being capable of more than the processing being replicated by a computer, and mass being poorly correlated with capacity for computation (especially across tissue which is in different parts of the body).
One might straightforwardly improve upon this estimate by extrapolating from other parts of the brain in a similar way, or from calculating how much information could feasibly be communicated in patterns of neuron firing (assuming these were the main components contributing to relevant computation).
The relationship between hardware and software
Suppose that you have accurately estimated how much computation the brain does. The argument above treats this as a lower bound on when human-level intelligence will arrive. This appears to rest on a model in which there is a certain level of hardware and a certain level of software that you need, and when you have them both you will have human-level AI.
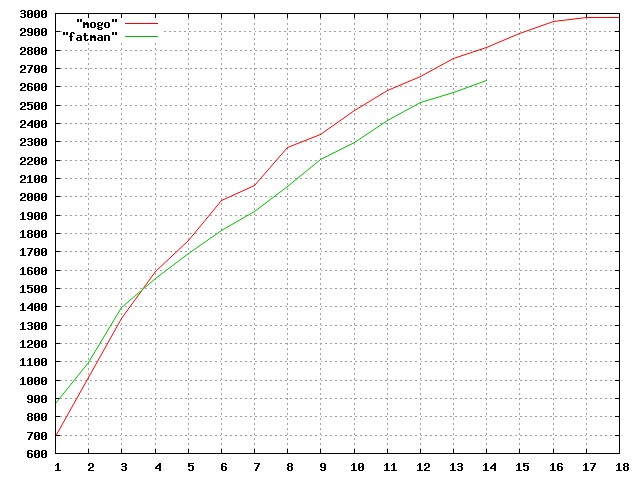
In reality, the same behavior can often be achieved with different combinations of hardware and software. For instance (as shown in figure 1), you can achieve the same Elo in Go using top of the range software (MoGo) and not much hardware (enough for 64 simulations) or weak software (FatMan) and much more hardware (enough for 1024 simulations, which probably take less hardware each than those used for the sophisticated program). The horizontal axis is doublings of hardware, but FatMan begins with much more hardware.
In Go we thus have a picture of indifference curves something like this:
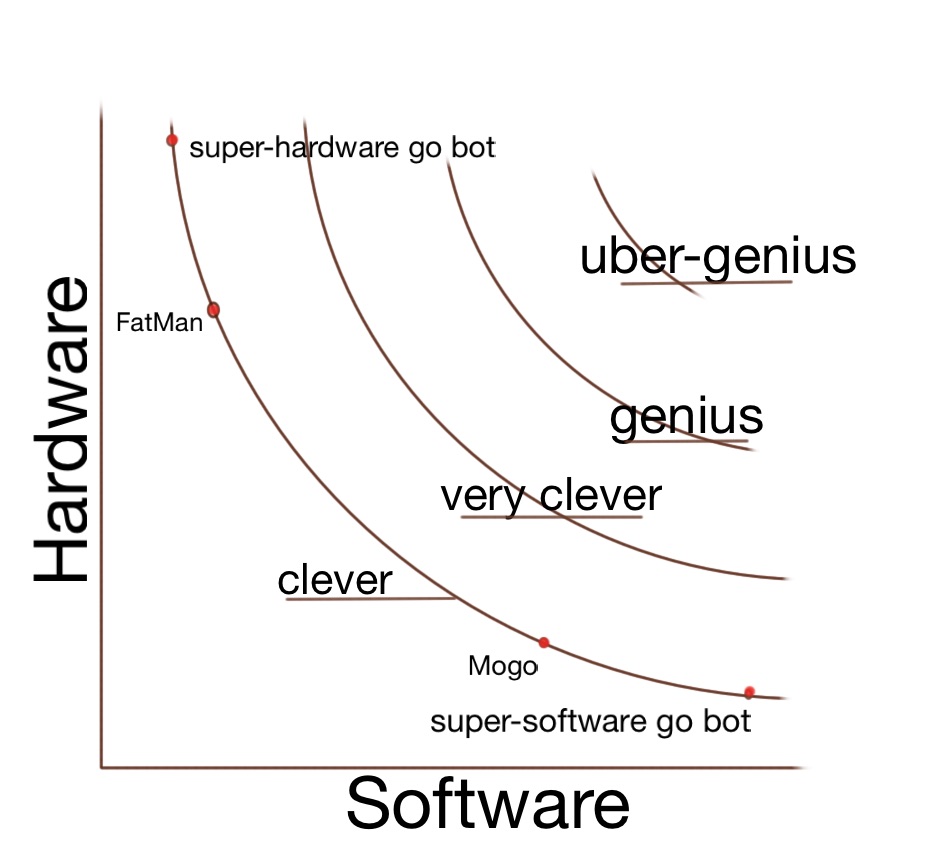
Go is not much like general intelligence, but the claim is that software in general has this character. If this is true, it suggests that the first human-level AI designed by human engineers might easily use much more or much less hardware than the human brain. This is illustrated in figure 3. Our trajectory of software and hardware progress could run into the frontier of human-level ability above or below human-level. If our software engineering is more sophisticated than that of evolution at the point where we hit the frontier, we would reach human-level AI with much less than ‘human-equivalent’ hardware.

As an aside, if we view the human brain as a chess playing machine, an analog to the argument outlined earlier in the post suggests that we should achieve human-level chess playing at human-equivalent hardware. We in fact achieved it much earlier, because indeed humans can program a chess player more efficiently than evolution did when it programmed humans. This is obviously in part because the human brain was not designed to play chess, and is mostly for other things. However, it’s not obvious that the human brain was largely designed for artificial intelligence research either, suggesting economic dynamite such as this might also arrive without ‘human-level’ hardware.
I don’t really know how good current human software engineering is compared to evolution, when they set their minds to the same tasks. I don’t think I have particularly strong reason to think they are about the same. Consequently, it seems I don’t seem to have strong reason to expect hardware equivalent to the brain is a particularly important benchmark (though if I’m truly indifferent between expecting human engineers to be better or worse, human-level hardware is indeed my median estimate).
Human equivalent hardware might be more important however: I said nothing about how hardware trades off against software. If the frontier of human-level hardware/software combinations is more like that in figure 4 below than figure 3, a very large range of software sophistication corresponds to human-level AI occurring at roughly similar levels of hardware, which means at roughly similar times. If this is so, then the advent of human-level hardware is a good estimate for when AI will arrive, because AI would arrive around then for a large range of levels of software sophistication.

The curve could also look opposite however, with the level of software sophistication being much more important than available hardware. I don’t know of strong evidence either way, so for now the probability of human-level AI at around the time we hit human-level hardware only seems moderately elevated.
The shape of the hardware/software frontier we have been discussing could be straightforwardly examined for a variety of software, using similar data to that presented for Go above. Or we might find that this ‘human-level frontier’ picture is not a useful model. The general nature of such frontiers seem highly informative about the frontier for advanced AI. I have not seen such data for anything other than parts of it for chess and Go. If anyone else is aware of such a thing, I would be interested to see it.
Costs
Will there be human-level AI when sufficient hardware (and software) is available at the cost of a supercomputer? At the cost of a human? At the cost of a laptop?
Price estimates used in this kind of calculation often seem to be chosen to be conservative—low prices so that the audience can be confident that an AI would surely be built if it were that cheap. For instance, when will human-level hardware be available for $1,000? While this is helpful for establishing an upper bound on the date, it does not seem plausible as a middling estimate. If human-level AI could be built for a million dollars instead of a thousand, it would still be done in a flash, and this corresponds to a difference of around fifteen years.
This is perhaps the easiest part of such an estimate to improve, with a review of how much organizations are generally willing to spend on large, valuable, risky projects.
***
In sum, this line of reasoning seems to be a reasonable start. As it stands, it probably produces wildly inaccurate estimates, and appears to be misguided in its implicit model of how hardware and software relate to each other. However it is a good beginning that could be incrementally improved into a fairly well informed estimate, with relatively modest research efforts. Which is just the kind of thing one wants to find among previous efforts to answer one’s question.



3 Trackbacks / Pingbacks