By Katja Grace, 8 June 2017
We put the main results of our survey of machine learning researchers on AI timelines online recently—see here for the paper.
Apologies for the delay—we are trying to avoid spoiling the newsworthiness of the results for potential academic publishers, lest they stop being potential academic publishers. But some places are ok with preprints on arXiv, so now we have one. And that means we can probably share some other things too.
There is actually a lot of stuff that isn’t in the paper, and it might take a little while for everything to be released. (The spreadsheet I’m looking at has 344 columns, and more than half of them represent boxes that people could write things in. And for many combinations of boxes, there are interesting questions to be asked.) We hope to share the whole dataset sometime soon, minus a few de-anonymizing bits. As we release more results, I’ll add them to our page about the survey.
The main interesting results so far, as I see them:
- Comparable forecasts seem to be later than in past surveys. in the other surveys we know of, the median dates for a 50% chance of something like High-Level Machine Intelligence (HLMI) range from 2035 to 2050. Here the median answer to the most similar question puts a 50% chance of HLMI in 2057 (this isn’t in the paper—it is just the median response to the HLMI question asked using the ‘fixed probabilities framing’, i.e. the way it has been asked before). This seems surprising to me given the progress machine learning has seen since last survey, but less surprising because we changed the definition of HLMI, in part fearing it had previously been interpreted to mean a relatively low level of performance.
- Asking people about specific jobs massively changes HLMI forecasts. When we asked some people when AI would be able to do several specific human occupations, and then all human occupations (presumably a subset of all tasks), they gave very much later timelines than when we just asked about HLMI straight out. For people asked to give probabilities for certain years, the difference was a factor of a thousand twenty years out! (10% vs. 0.01%) For people asked to give years for certain probabilities, the normal way of asking put 50% chance 40 years out, while the ‘occupations framing’ put it 90 years out. (These are all based on straightforward medians, not the complicated stuff in the paper.)
- People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M. We saw this in the straightforward HLMI question, and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.
- Lots of ‘narrow’ AI milestones are forecast in the next decade as likely as not. These are interesting, because most of them haven’t been forecast before to my knowledge, and many of them have social implications. For instance, if in a decade machines can not only write pop hits as well as Taylor Swift can, but can write pop hits that sound like Taylor Swift as well as Taylor Swift can—and perhaps faster, more cheaply, and on Spotify—then will that be the end of the era of superstar musicians? This perhaps doesn’t rival human extinction risks for importance, but human extinction risks do not happen in a vacuum (except one) and there is something to be said for paying attention to big changes in the world other than the one that matters most.
- There is broad support among ML researchers for the premises and conclusions of AI safety arguments. Two thirds of them say the AI risk problem described by Stuart Russell is at least moderately important, and a third say it is at least as valuable to work on as other problems in the field. The median researcher thinks AI has a one in twenty chance of being extremely bad on net. Nearly half of researchers want to see more safety research than we currently have (compared to only 11% who think we are already prioritizing safety too much). There has been a perception lately that AI risk has moved to being a mainstream concern among AI researchers, but it is hard to tell from voiced opinion whether one is hearing from a loud minority or the vocal tip of an opinion iceberg. So it is interesting to see this perception confirmed with survey data.
- Researchers’ predictions vary a lot. That is pretty much what I expected, but it is still important to know. Interestingly (and not in the paper), researchers don’t seem to be aware that their predictions vary a lot. More than half of respondents guess that they disagree ‘not much’ with the typical AI researcher about when HLMI will exist (vs. a moderate amount, or a lot).
- Researchers who studied in Asia have much shorter timelines than those who studied in North Amercia. In terms of the survey’s ‘aggregate prediction’ thing, which is basically a mean, the difference is 30 years (Asia) vs. 74 years (North America). (See p5)
- I feel like any circumstance where a group of scientists guesses that the project they are familiar with has a 5% chance of outcomes near ‘human extinction’ levels of bad is worthy of special note, though maybe it is not actually that surprising, and could easily turn out to be misuse of small probabilities or something.
Some notes on interpreting the paper:
- The milestones in the timeline and in the abstract are from three different sets of questions. There seems to be a large framing effect between two of them—full automation of labor is logically required to be before HLMI, and yet it is predicted much later—and it is unclear whether people answer the third set of questions (about narrow tasks) more like the one about HLMI or more like the one about occupations. Plus even if there were no framing effect to worry about, we should expect milestones about narrow tasks to be much earlier than milestones about very similar sounding occupations. For instance, if there were an occupation ‘math researcher’, it should be later than the narrow task summarized here as ‘math research’. So there is a risk of interpreting the figure as saying AI research is harder than math research, when really the ‘-er’ is all-important. So to help avoid confusion, here is the timeline colored in by which set of questions each milestone came from. The blue one was asked on its own. The orange ones were always asked together: first all four occupations, then they were asked for an occupation they expected to be very late, and when they expected it, then full automation of labor. The pink milestones were randomized, so that each person got four. There are a lot more pink milestones not included here, but included in the long table at the end of the paper.
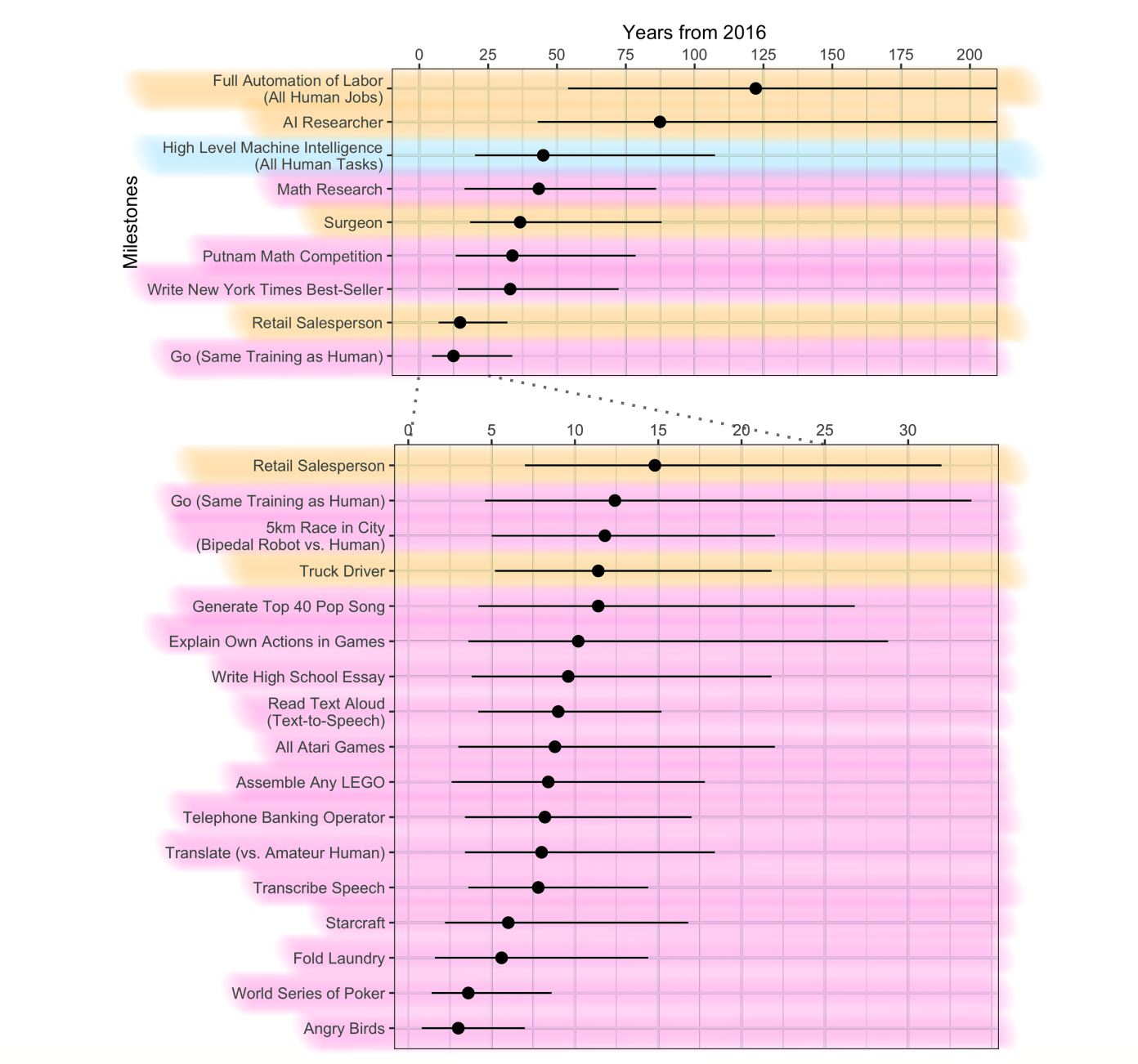
- In Figure 2 and Table S5 I believe the word ‘median’ means we are talking about the ‘50% chance of occurring’ number, and the dates given are this ‘median’ (50% chance) date for a distribution that was made by averaging together all of the different people’s distributions (or what we guess their distributions are like from three data points).
- Here are the simple median numbers for human level AI, for each combination of framings. I am sorry that the table is not simple. There are two binary framing choices—whether to ask about probabilities or years, and whether to ask about a bunch of occupations and then all occupations, or just to ask about HLMI. Each framing is in a different column, and bold blue numbers are the medians of probabilities or years given by respondents to match the years or probabilities that are non-bold numbers on the same line. e.g. the first line says that the median person seeing the fixed years, occupations framing said that in ten years there was 0% chance, and the median person seeing the fixed years, HLMI framing said that in ten years there would be a 1% chance of HLMI.
Time Probability Fixed years, Occs Fixed years, HLMI 10 years 0% 1% 20 years 0.01% 10% 40 years 30% 50 years 3% 15 years 50 years 10% 40 years 90 years 50% 100 years 200 years 90% Fixed probs, HLMI Fixed probs, Occs - All of the questions are here. This is the specific statement of Stuart Russell’s quote that many questions referred to:

Stuart Russell summarizes an argument for why highly advanced AI might pose a risk as follows:
The primary concern [with highly advanced AI] is not spooky emergent consciousness but simply the ability to make high-quality decisions. Here, quality refers to the expected outcome utility of actions taken […]. Now we have a problem:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. This is essentially the old story of the genie in the lamp, or the sorcerer’s apprentice, or King Midas: you get exactly what you ask for, not what you want.
8 June 2017



please expand acronym HLMI once
Done, thanks.
> People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M.
I hypothesize that people don’t really think about the fact that the current year is 2017 and they implicitly round it off to either 2000 or 2010, which would explain this.
> For people asked to give probabilities for certain years, the difference was a factor of a thousand twenty years out! (10% vs. 0.01%)
Sounds like a great betting arbitrage opportunity! 😀
Some other comments:
* Naturally “AI researcher” is the hardest job to replace, according to this.
* Quite a gap between time to replace the hardest job (AI researcher) vs. time to replace all jobs. I wonder what surveyors expect will be the last job to be automated?
* Median prediction for writing a high school essay is 10 years whereas writing a bestseller is close to 30 years. Surely writing a high school essay is almost all of the way to writing a bestseller?