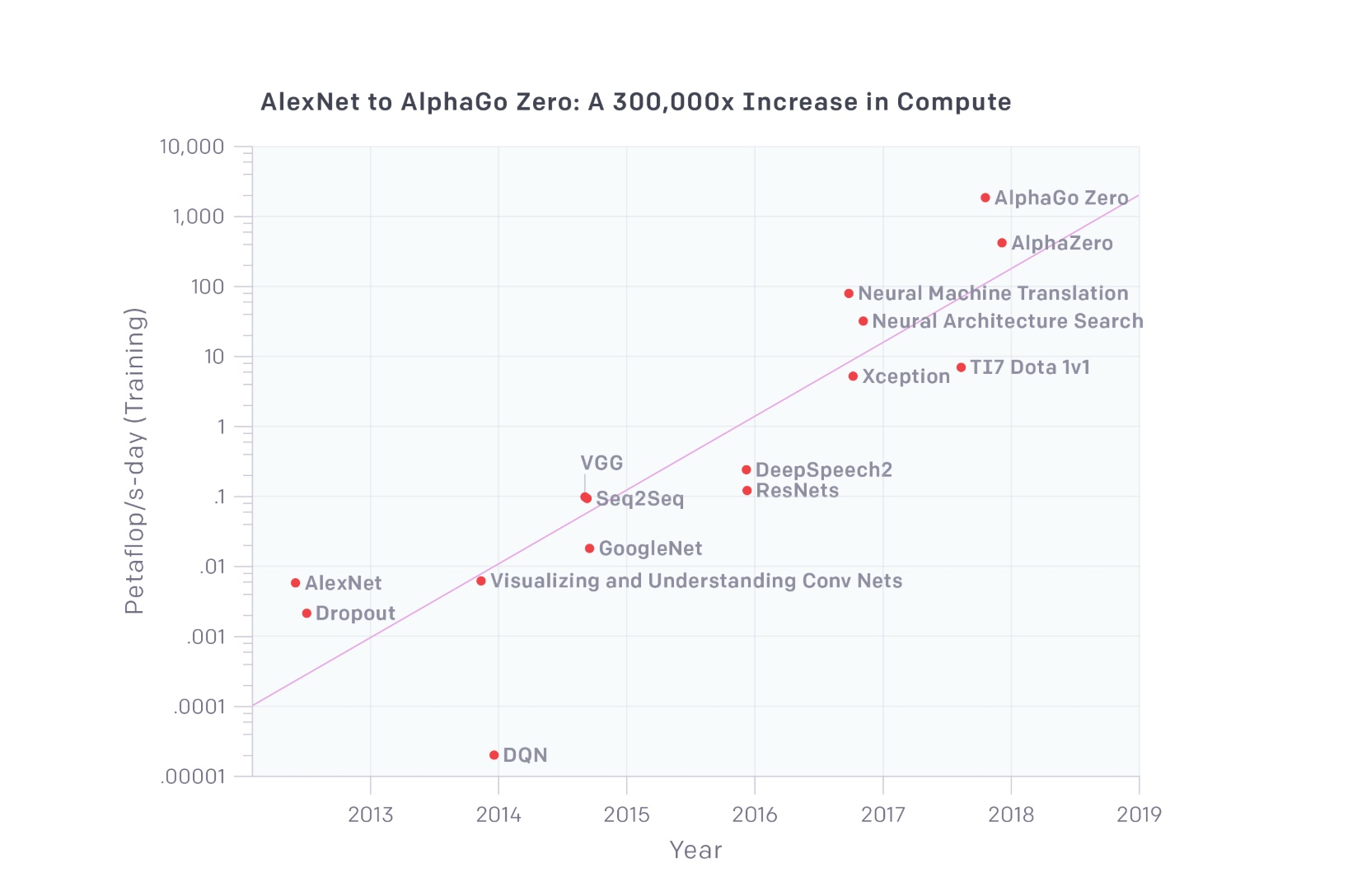
…since 2012, the amount of compute used in the largest AI training runs has been increasing exponentially with a 3.5 month-doubling time (by comparison, Moore’s Law had an 18-month doubling period). Since 2012, this metric has grown by more than 300,000x (an 18-month doubling period would yield only a 12x increase)…
They give the following figure, and some of their calculations. We have not verified their calculations, or looked for other reports on this issue.
Figure 1: Originally captioned: The chart shows the total amount of compute, in petaflop/s-days, that was used to train selected results that are relatively well known, used a lot of compute for their time, and gave enough information to estimate the compute used. A petaflop/s-day (pfs-day) consists of performing 1015 neural net operations per second for one day, or a total of about 1020 operations. The compute-time product serves as a mental convenience, similar to kW-hr for energy. We don’t measure peak theoretical FLOPS of the hardware but instead try to estimate the number of actual operations performed. We count adds and multiplies as separate operations, we count any add or multiply as a single operation regardless of numerical precision (making “FLOP” a slight misnomer), and we ignore ensemble models. Example calculations that went into this graph are provided in this appendix. Doubling time for line of best fit shown is 3.43 months.
We welcome suggestions for this page or anything on the site via our feedback box, though will not address all of them.
An analysis of historical growth supports the possibility of radical increases in growth rate. Naive extrapolation of long-term trends would suggest massive increases in growth rate over the coming century, although growth over the last
Published 23 January 2014, last updated Aug 7 2022 ‘Human-level AI’ refers to AI which can reproduce everything a human can do, approximately. Several variants of this concept are worth distinguishing. Contents DetailsVariations in the meaning
In the course of our work, we have noticed a number of empirical questions which bear on our forecasts and might be (relatively) cheap to resolve. In the future we hope to address some of