Published 3 August 2022; last updated 3 August 2022
This page is out-of-date. Visit the updated version of this page on our wiki.
The 2022 Expert Survey on Progress in AI (2022 ESPAI) is a survey of machine learning researchers that AI Impacts ran in June-August 2022.
Details
Background
The 2022 ESPAI is a rerun of the 2016 Expert Survey on Progress in AI that researchers at AI Impacts previously collaborated on with others. Almost all of the questions were identical, and both surveyed authors who recently published in NeurIPS and ICML, major machine learning conferences.
Zhang et al ran a followup survey in 2019 (published in 2022)1 however they reworded or altered many questions, including the definitions of HLMI, so much of their data is not directly comparable to that of the 2016 or 2022 surveys, especially in light of large potential for framing effects observed.
Methods
Population
We contacted approximately 4271 researchers who published at the conferences NeurIPS or ICML in 2021. These people were selected by taking all of the authors at those conferences and randomly allocating them between this survey and a survey being run by others. We then contacted those whose email addresses we could find. We found email addresses in papers published at those conferences, in other public data, and in records from our previous survey and Zhang et al 2022. We received 738 responses, some partial, for a 17% response rate.
Participants who previously participated in the the 2016 ESPAI or Zhang et al surveys received slightly longer surveys, and received questions which they had received in past surveys (where random subsets of questions were given), rather than receiving newly randomized questions. This was so that they could also be included in a ‘matched panel’ survey, in which we contacted all researchers who completed the 2016 ESPAI or Zhang et al surveys, to compare responses from exactly the same samples of researchers over time. These surveys contained additional questions matching some of those in the Zhang et al survey.
Contact
We invited the selected researchers to take the survey via email. We accepted responses between June 12 and August 3, 2022.
Questions
The full list of survey questions is available below, as exported from the survey software. The export does not preserve pagination, or data about survey flow. Participants received randomized subsets of these questions, so the survey each person received was much shorter than that shown below.
A small number of changes were made to questions since the 2016 survey (list forthcoming).
Definitions
‘HLMI’ was defined as follows:
The following questions ask about ‘high–level machine intelligence’ (HLMI). Say we have ‘high-level machine intelligence’ when unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
Results
Data
The anonymized dataset is available here.
Summary of results
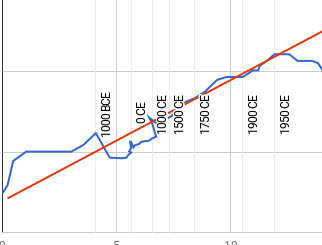
- The aggregate forecast time to a 50% chance of HLMI was 37 years, i.e. 2059 (not including data from questions about the conceptually similar Full Automation of Labor, which in 2016 received much later estimates). This timeline has become about eight years shorter in the six years since 2016, when the aggregate prediction put 50% probability at 2061, i.e. 45 years out. Note that these estimates are conditional on “human scientific activity continu[ing] without major negative disruption.”
- The median respondent believes the probability that the long-run effect of advanced AI on humanity will be “extremely bad (e.g., human extinction)” is 5%. This is the same as it was in 2016 (though Zhang et al 2022 found 2% in a similar but non-identical question). Many respondents were substantially more concerned: 48% of respondents gave at least 10% chance of an extremely bad outcome. But some much less concerned: 25% put it at 0%.
- The median respondent believes society should prioritize AI safety research “more” than it is currently prioritized. Respondents chose from “much less,” “less,” “about the same,” “more,” and “much more.” 69% of respondents chose “more” or “much more,” up from 49% in 2016.
- The median respondent thinks there is an “about even chance” that a stated argument for an intelligence explosion is broadly correct. 54% of respondents say the likelihood that it is correct is “about even,” “likely,” or “very likely” (corresponding to probability >40%), similar to 51% of respondents in 2016. The median respondent also believes machine intelligence will probably (60%) be “vastly better than humans at all professions” within 30 years of HLMI, and the rate of global technological improvement will probably (80%) dramatically increase (e.g., by a factor of ten) as a result of machine intelligence within 30 years of HLMI.
High-level machine intelligence timelines
The aggregate forecast time to HLMI was 36.6 years, conditional on “human scientific activity continu[ing] without major negative disruption.” and considering only questions using the HLMI definition. We have not yet analyzed data about the conceptually similar Full Automation of Labor (FAOL), which in 2016 prompted much later timeline estimates. Thus this timeline figure is expected to be low relative to an overall estimate from this survey.
This aggregate is the 50th percentile date in an equal mixture of probability distributions created by fitting a gamma distribution to each person’s answers to three questions either about the probability of HLMI occurring by a given year or the year at which a given probability would obtain.

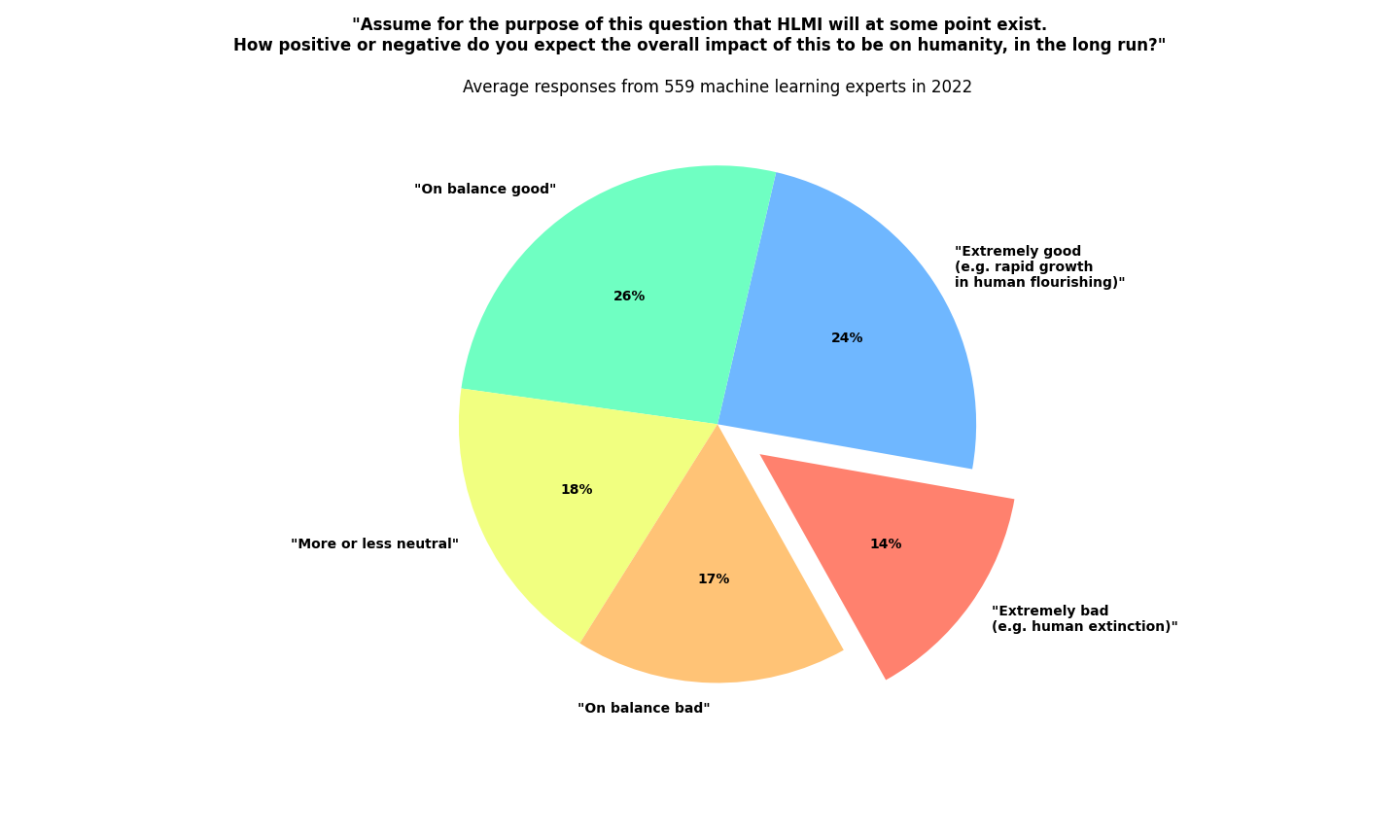
Impacts of HLMI
Question
Participants were asked:
Assume for the purpose of this question that HLMI will at some point exist. How positive or negative do you expect the overall impact of this to be on humanity, in the long run? Please answer by saying how probable you find the following kinds of impact, with probabilities adding to 100%:
______ Extremely good (e.g. rapid growth in human flourishing) (1)
______ On balance good (2)
______ More or less neutral (3)
______ On balance bad (4)
______ Extremely bad (e.g. human extinction) (5)
Answers
Medians:
- Extremely good: 10%
- On balance good: 20%
- More or less neutral: 15%
- On balance bad: 10%
- Extremely bad: 5%
Means:
- Extremely good: 24%
- On balance good: 26%
- More or less neutral: 18%
- On balance bad: 17%
- Extremely bad: 14%
Intelligence explosion
Probability of dramatic technological speedup
Question
Participants were asked:
Assume that HLMI will exist at some point. How likely do you then think it is that the rate of global technological improvement will dramatically increase (e.g. by a factor of ten) as a result of machine intelligence:
Within two years of that point? ___% chance
Within thirty years of that point? ___% chance
Answers
Median P(within two years) = 20% (20% in 2016)
Median P(within thirty years) = 80% (80% in 2016)
Probability of superintelligence
Question
Participants were asked:
Assume that HLMI will exist at some point. How likely do you think it is that there will be machine intelligence that is vastly better than humans at all professions (i.e. that is vastly more capable or vastly cheaper):
Within two years of that point? ___% chance
Within thirty years of that point? ___% chance
Answers
Median P(…within two years) = 10% (10% in 2016)
Median P(…within thirty years) = 60% (50% in 2016)
Chance that the intelligence explosion argument is about right
Question
Participants were asked:
Some people have argued the following:
If AI systems do nearly all research and development, improvements in AI will accelerate the pace of technological progress, including further progress in AI.
Over a short period (less than 5 years), this feedback loop could cause technological progress to become more than an order of magnitude faster.
How likely do you find this argument to be broadly correct?
- Quite unlikely (0-20%)
- Unlikely (21-40%)
- About even chance (41-60%)
- Likely (61-80%)
- Quite likely (81-100%)
Answers
- 20% quite unlikely (25% in 2016)
- 26% unlikely (24% in 2016)
- 21% about even chance (22% in 2016)
- 26% likely (17% in 2016)
- 7% quite likely (12% in 2016)
Existential risk
In an above question, participants’ credence in “extremely bad” outcomes of HLMI have median 5% and mean 14%. To better clarify what participants mean by this, we also asked a subset of participants one of the following questions, which did not appear in the 2016 survey:
Extinction from AI
Participants were asked:
What probability do you put on future AI advances causing human extinction or similarly permanent and severe disempowerment of the human species?
Answers
Median 5%.
Extinction from human failure to control AI
Participants were asked:
What probability do you put on human inability to control future advanced AI systems causing human extinction or similarly permanent and severe disempowerment of the human species?
Answers
Median 10%.
This question is more specific and thus necessarily less probable than the previous question, but it was given a higher probability at the median. This could be due to noise (different random subsets of respondents received the questions, so there is no logical requirement that their answers cohere), or due to the representativeness heuristic.
Safety
General safety
Question
Participants were asked:
Let ‘AI safety research’ include any AI-related research that, rather than being primarily aimed at improving the capabilities of AI systems, is instead primarily aimed at minimizing potential risks of AI systems (beyond what is already accomplished for those goals by increasing AI system capabilities).
Examples of AI safety research might include:
- Improving the human-interpretability of machine learning algorithms for the purpose of improving the safety and robustness of AI systems, not focused on improving AI capabilities
- Research on long-term existential risks from AI systems
- AI-specific formal verification research
- Policy research about how to maximize the public benefits of AI
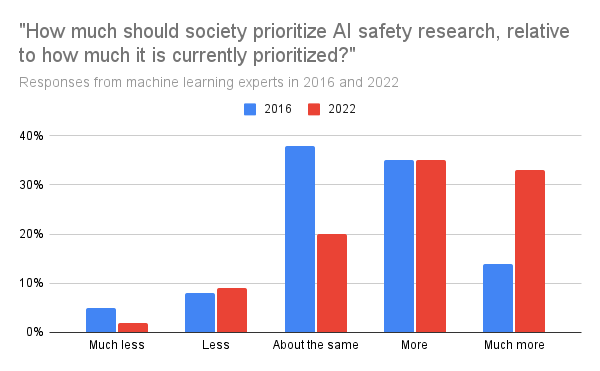
How much should society prioritize AI safety research, relative to how much it is currently prioritized?
- Much less
- Less
- About the same
- More
- Much more
Answers
- Much less: 2% (5% in 2016)
- Less: 9% (8% in 2016)
- About the same: 20% (38% in 2016)
- More: 35% (35% in 2016)
- Much more: 33% (14% in 2016)
69% of respondents think society should prioritize AI safety research more or much more, up from 49% in 2016.
Stuart Russell’s problem
Question
Participants were asked:
Stuart Russell summarizes an argument for why highly advanced AI might pose a risk as follows:
The primary concern [with highly advanced AI] is not spooky emergent consciousness but simply the ability to make high-quality decisions. Here, quality refers to the expected outcome utility of actions taken […]. Now we have a problem:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. This is essentially the old story of the genie in the lamp, or the sorcerer’s apprentice, or King Midas: you get exactly what you ask for, not what you want.
Do you think this argument points at an important problem?
- No, not a real problem.
- No, not an important problem.
- Yes, a moderately important problem.
- Yes, a very important problem.
- Yes, among the most important problems in the field.
How valuable is it to work on this problem today, compared to other problems in AI?
- Much less valuable
- Less valuable
- As valuable as other problems
- More valuable
- Much more valuable
How hard do you think this problem is compared to other problems in AI?
- Much easier
- Easier
- As hard as other problems
- Harder
- Much harder
Answers
Importance:
- No, not a real problem: 4%
- No, not an important problem: 14%
- Yes, a moderately important problem: 24%
- Yes, a very important problem: 37%
- Yes, among the most important problems in the field: 21%
Value today:
- Much less valuable: 10%
- Less valuable: 30%
- As valuable as other problems: 33%
- More valuable: 19%
- Much more valuable: 8%
Hardness:
- Much easier: 5%
- Easier: 9%
- As hard as other problems: 29%
- Harder: 31%
- Much harder: 26%
Contributions
The survey was run by Katja Grace and Ben Weinstein-Raun. Data analysis was done by Zach Stein-Perlman and Ben Weinstein-Raun. This page was written by Zach Stein-Perlman and Katja Grace.
We thank many colleagues and friends for help, discussion and encouragement, including John Salvatier, Nick Beckstead, Howie Lempel, Joe Carlsmith, Leopold Aschenbrenner, Ramana Kumar, Jimmy Rintjema, Jacob Hilton, Ajeya Cotra, Scott Siskind, Chana Messinger, Noemi Dreksler, and Baobao Zhang.
We also thank the expert participants who spent time sharing their impressions with us, including:
Michał Zając
Morten Goodwin
Yue Sun
Ningyuan Chen
Egor Kostylev
Richard Antonello
Elia Turner
Andrew C Li
Zachary Markovich
Valentina Zantedeschi
Michael Cooper
Thomas A Keller
Marc Cavazza
Richard Vidal
David Lindner
Xuechen (Chen) Li
Alex M. Lamb
Tristan Aumentado-Armstrong
Ferdinando Fioretto
Alain Rossier
Wentao Zhang
Varun Jampani
Derek Lim
Muchen Li
Cong Hao
Yao-Yuan Yang
Linyi Li
Stéphane D’Ascoli
Lang Huang
Maxim Kodryan
Hao Bian
Orestis Paraskevas
David Madras
Tommy Tang
Li Sun
Stefano V Albrecht
Tristan Karch
Muhammad A Rahman
Runtian Zhai
Benjamin Black
Karan Singhal
Lin Gao
Ethan Brooks
Cesar Ferri
Dylan Campbell
Xujiang Zhao
Jack Parker-Holder
Michael Norrish
Jonathan Uesato
Yang An
Maheshakya Wijewardena
Ulrich Neumann
Lucile Ter-Minassian
Alexander Matt Turner
Subhabrata Dutta
Yu-Xiang Wang
Yao Zhang
Joanna Hong
Yao Fu
Wenqing Zheng
Louis C Tiao
Hajime Asama
Chengchun Shi
Moira R Dillon
Yisong Yue
Aurélien Bellet
Yin Cui
Gang Hua
Jongheon Jeong
Martin Klissarov
Aran Nayebi
Fabio Maria Carlucci
Chao Ma
Sébastien Gambs
Rasoul Mirzaiezadeh
Xudong Shen
Julian Schrittwieser
Adhyyan Narang
Fuxin Li
Linxi Fan
Johannes Gasteiger
Karthik Abinav Sankararaman
Patrick Mineault
Akhilesh Gotmare
Jibang Wu
Mikel Landajuela
Jinglin Liu
Qinghua Hu
Noah Siegel
Ashkan Khakzar
Nathan Grinsztajn
Julian Lienen
Xiaoteng Ma
Mohamad H Danesh
Ke ZHANG
Feiyu Xiong
Wonjae Kim
Michael Arbel
Piotr Skowron
Lê-Nguyên Hoang
Travers Rhodes
Liu Ziyin
Hossein Azizpour
Karl Tuyls
Hangyu Mao
Yi Ma
Junyi Li
Yong Cheng
Aditya Bhaskara
Xia Li
Danijar Hafner
Brian Quanz
Fangzhou Luo
Luca Cosmo
Scott Fujimoto
Santu Rana
Michael Curry
Karol Hausman
Luyao Yuan
Samarth Sinha
Matthew McLeod
Hao Shen
Navid Naderializadeh
Alessio Micheli
Zhenbang You
Van Huy Vo
Chenyang Wu
Thanard Kurutach
Vincent Conitzer
Chuang Gan
Chirag Gupta
Andreas Schlaginhaufen
Ruben Ohana
Luming Liang
Marco Fumero
Paul Muller
Hana Chockler
Ming Zhong
Jiamou Liu
Sumeet Agarwal
Eric Winsor
Ruimeng Hu
Changjian Shui
Yiwei Wang
Joey Tianyi Zhou
Anthony L. Caterini
Guillermo Ortiz-Jimenez
Iou-Jen Liu
Jiaming Liu
Michael Perlmutter
Anurag Arnab
Ziwei Xu
John Co-Reyes
Aravind Rajeswaran
Roy Fox
Yong-Lu Li
Carl Yang
Divyansh Garg
Amit Dhurandhar
Harris Chan
Tobias Schmidt
Robi Bhattacharjee
Marco Nadai
Reid McIlroy-Young
Wooseok Ha
Jesse Mu
Neale Ratzlaff
Kenneth Borup
Binghong Chen
Vikas Verma
Walter Gerych
Shachar Lovett
Zhengyu Zhao
Chandramouli Chandrasekaran
Richard Higgins
Nicholas Rhinehart
Blaise Agüera Y Arcas
Santiago Zanella-Beguelin
Dian Jin
Scott Niekum
Colin A. Raffel
Sebastian Goldt
Yali Du
Bernardo Subercaseaux
Hui Wu
Vincent Mallet
Ozan Özdenizci
Timothy Hospedales
Lingjiong Zhu
Cheng Soon Ong
Shahab Bakhtiari
Huan Zhang
Banghua Zhu
Byungjun Lee
Zhenyu Liao
Adrien Ecoffet
Vinay Ramasesh
Jesse Zhang
Soumik Sarkar
Nandan Kumar Jha
Daniel S Brown
Neev Parikh
Chen-Yu Wei
David K. Duvenaud
Felix Petersen
Songhua Wu
Huazhu Fu
Roger B Grosse
Matteo Papini
Peter Kairouz
Burak Varici
Fabio Roli
Mohammad Zalbagi Darestani
Jiamin He
Lys Sanz Moreta
Xu-Hui Liu
Qianchuan Zhao
Yulia Gel
Jan Drgona
Sajad Khodadadian
Takeshi Teshima
Igor T Podolak
Naoya Takeishi
Man Shun Ang
Mingli Song
Jakub Tomczak
Lukasz Szpruch
Micah Goldblum
Graham W. Taylor
Tomasz Korbak
Maheswaran Sathiamoorthy
Lan-Zhe Guo
Simone Fioravanti
Lei Jiao
Davin Choo
Kristy Choi
Varun Nair
Rayana Jaafar
Amy Greenwald
Martin V. Butz
Aleksey Tikhonov
Samuel Gruffaz
Yash Savani
Rui Chen
Ke Sun
Suggested citation
Zach Stein-Perlman, Benjamin Weinstein-Raun, Katja Grace, “2022 Expert Survey on Progress in AI.” AI Impacts, 3 Aug. 2022. https://aiimpacts.org/2022-expert-survey-on-progress-in-ai/.
Notes
- Zhang, Baobao, Noemi Dreksler, Markus Anderljung, Lauren Kahn, Charlie Giattino, Allan Dafoe, and Michael Horowitz. “Forecasting AI Progress: Evidence from a Survey of Machine Learning Researchers,” June 8, 2022. https://doi.org/10.48550/arXiv.2206.04132.