Published June 2016; last substantial update before Oct 2017
The 2016 Expert Survey on Progress in AI is a survey of machine learning researchers that Katja Grace and John Salvatier of AI Impacts ran in collaboration with Allan Dafoe, Baobao Zhang, and Owain Evans in 2016.
Details
Some survey results are reported in When Will AI Exceed Human Performance? Evidence from AI Experts. This page reports on results from those questions more fully, and results from some questions not included in the paper.
The full list of survey questions is available here (pdf). Participants received randomized subsets of these questions.
Definitions
Throughout the survey, ‘HLMI’ was defined as follows:
The following questions ask about ‘high–level machine intelligence’ (HLMI). Say we have ‘high-level machine intelligence’ when unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
Summary of results
Below is a table of summary results from the paper (the paper contains more results).
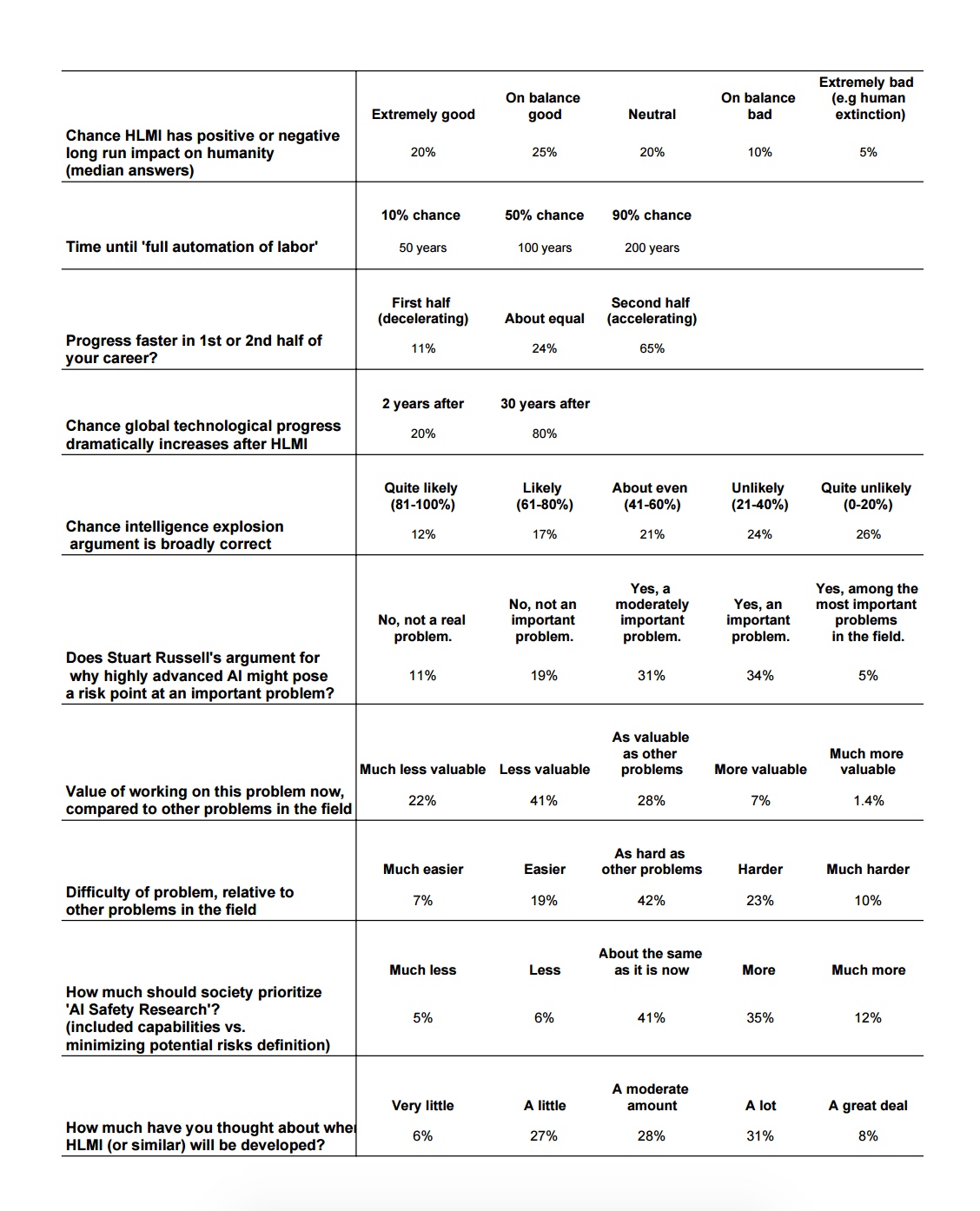
Some key interesting results, from our blog post:
- Comparable forecasts seem to be later than in past surveys. in the other surveys we know of, the median dates for a 50% chance of something like High-Level Machine Intelligence (HLMI) range from 2035 to 2050. Here the median answer to the most similar question puts a 50% chance of HLMI in 2057 (this isn’t in the paper—it is just the median response to the HLMI question asked using the ‘fixed probabilities framing’, i.e. the way it has been asked before). This seems surprising to me given the progress machine learning has seen since last survey, but less surprising because we changed the definition of HLMI, in part fearing it had previously been interpreted to mean a relatively low level of performance.
- Asking people about specific jobs massively changes HLMI forecasts. When we asked some people when AI would be able to do several specific human occupations, and then all human occupations (presumably a subset of all tasks), they gave very much later timelines than when we just asked about HLMI straight out. For people asked to give probabilities for certain years, the difference was a factor of a thousand twenty years out! (10% vs. 0.01%) For people asked to give years for certain probabilities, the normal way of asking put 50% chance 40 years out, while the ‘occupations framing’ put it 90 years out. (These are all based on straightforward medians, not the complicated stuff in the paper.)
- People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M. We saw this in the straightforward HLMI question, and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.
- Lots of ‘narrow’ AI milestones are forecast in the next decade as likely as not. These are interesting, because most of them haven’t been forecast before to my knowledge, and many of them have social implications. For instance, if in a decade machines can not only write pop hits as well as Taylor Swift can, but can write pop hits that sound like Taylor Swift as well as Taylor Swift can—and perhaps faster, more cheaply, and on Spotify—then will that be the end of the era of superstar musicians? This perhaps doesn’t rival human extinction risks for importance, but human extinction risks do not happen in a vacuum (except one), and there is something to be said for paying attention to big changes in the world other than the one that matters most.
- There is broad support among ML researchers for the premises and conclusions of AI safety arguments. Two thirds of them say the AI risk problem described by Stuart Russell is at least moderately important, and a third say it is at least as valuable to work on as other problems in the field. The median researcher thinks AI has a one in twenty chance of being extremely bad on net. Nearly half of researchers want to see more safety research than we currently have (compared to only 11% who think we are already prioritizing safety too much). There has been a perception lately that AI risk has become a mainstream concern among AI researchers, but it is hard to tell from voiced opinion whether one is hearing from a loud minority or the vocal tip of an opinion iceberg. So it is interesting to see the perception of widespread support confirmed with survey data.
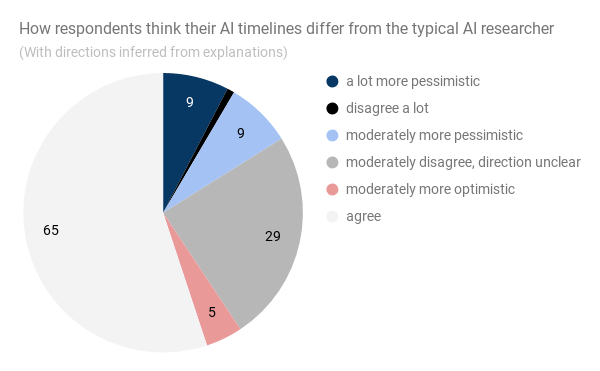
- Researchers’ predictions vary a lot. This is pretty much what I expected, but it is still important to know. Interestingly (and not in the paper), researchers don’t seem to be aware that their predictions vary a lot. More than half of respondents guess that they disagree ‘not much’ with the typical AI researcher about when HLMI will exist (vs. a moderate amount, or a lot).
- Researchers who studied in Asia have much shorter timelines than those who studied in North Amercia. In terms of the survey’s ‘aggregate prediction’ thing, which is basically a mean, the difference is 30 years (Asia) vs. 74 years (North America). (See p5)
- I feel like any circumstance where a group of scientists guesses that the project they are familiar with has a 5% chance of outcomes near ‘human extinction’ levels of bad is worthy of special note, though maybe it is not actually that surprising, and could easily turn out to be misuse of small probabilities or something.
Results
Human-level intelligence
Questions
We sought forecasts for something like human-level AI in three different ways, to reduce noise from unknown framing biases:
- Directly, using a question much like Müller and Bostrom’s, though with a refined definition of High-Level Machine Intelligence (HLMI).
- At the end of a sequence of questions about the automation of specific human occupations.
- Indirectly, with an ‘outside view’ approximation: by asking each person how long it has taken to make the progress to date in their subfield, and what fraction of the ground has been covered. This is Robin Hanson‘s approach, which he found suggested much longer timelines than those reached directly.
For the first two of these, we split people in half, and asked one half how many years until a certain chance of the event would obtain, and the other half what the chance was of the event occurring by specific dates. We call these methods ‘fixed probabilities’ and ‘fixed years’ framings throughout.
For the (somewhat long and detailed) specifics of these questions, see here or here (pdf).
Answers
The table and figure below show the median dates and probabilities given for the direct ‘HLMI’ question, and in the ‘via occupations’ questions, under both the fixed probabilities and fixed years framings.
| years until: | 10% | 50% | 90% | probability by: | 10 years | 20 years | 50 years |
| Truck Driver | 5 | 10 | 20 | 50% | 75% | 95% | |
| Surgeon | 10 | 30 | 50 | 5% | 20% | 50% | |
| Retail Salesperson | 5 | 13.5 | 20 | 30% | 60% | 91.5% | |
| AI Researcher | 25 | 50 | 100 | 0% | 1% | 10% | |
| Existing occupation among final to be automated | 50 | 100 | 200 | 0% | 0% | 3.5% | |
| Full Automation of labor | 50 | 90 | 200 | 0% | 0.01% | 3% | |
| HLMI | 15 | 40 | 100 | 1% | 10% | >30%* (30% in 40y) |
*Due to a typo, this question asked about 40 years rather than 50 years, so doesn’t match the others.
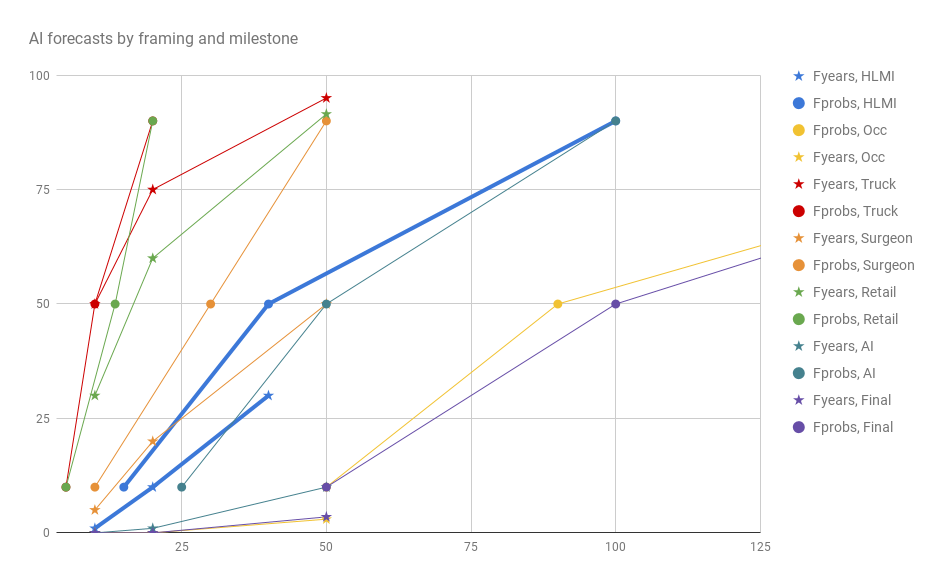
Interesting things to note:
- Fixed years framings (‘Fyears —‘, labeled with stars) universally produce later timelines.
- HLMI (thick blue lines) is logically required to be after full automation of labor (‘Occ’) yet is forecast much earlier than it, and earlier even than the specific occupation ‘AI researcher’.
- Even the more pessimistic Fyears estimates suggest retail salespeople have a good chance of being automated within 20 years, and are very likely to be within 50.
Intelligence Explosion
Probability of dramatic technological speedup
Question
Participants were asked1:
Assume that HLMI will exist at some point. How likely do you then think it is that the rate of global technological improvement will dramatically increase (e.g. by a factor of ten) as a result of machine intelligence:
Within two years of that point? ___% chance
Within thirty years of that point? ___% chance
Answers
Median P(…within two years) = 20%
Median P(…within thirty years) = 80%
Probability of superintelligence
Question
Participants were asked:
Assume that HLMI will exist at some point. How likely do you think it is that there will be machine intelligence that is vastly better than humans at all professions (i.e. that is vastly more capable or vastly cheaper):
Within two years of that point? ___% chance
Within thirty years of that point? ___% chance
Answers
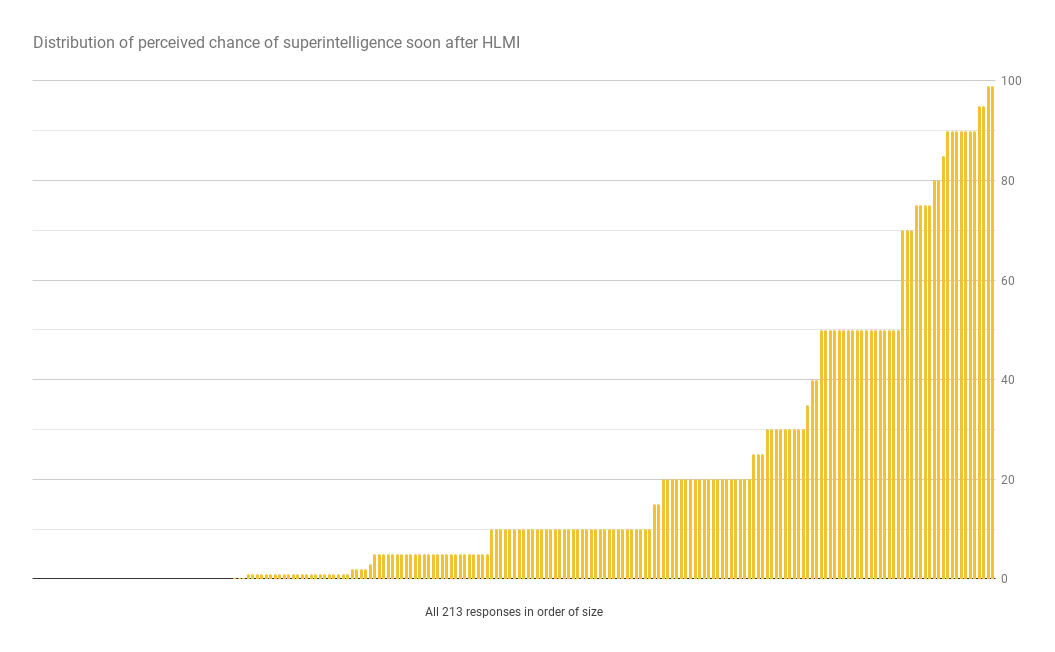
Median P(…within two years) = 10%
Median P(…within thirty years) = 50%
This is the distribution of answers to the former:
Chance that the intelligence explosion argument is about right
Question
Participants were asked:
Some people have argued the following:
If AI systems do nearly all research and development, improvements in AI will accelerate the pace of technological progress, including further progress in AI.
.
Over a short period (less than 5 years), this feedback loop could cause technological progress to become more than an order of magnitude faster.
How likely do you find this argument to be broadly correct?
-
- Quite unlikely (0-20%)
- Unlikely (21-40%)
- About even chance (41-60%)
- Likely (61-80%)
- Quite likely (81-100%)
Answers

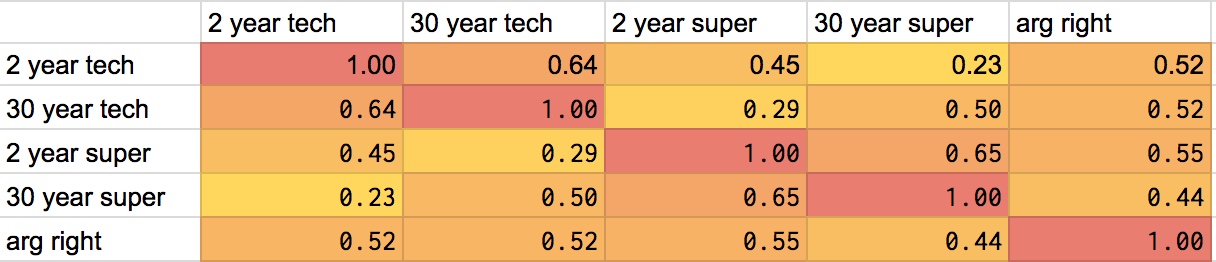
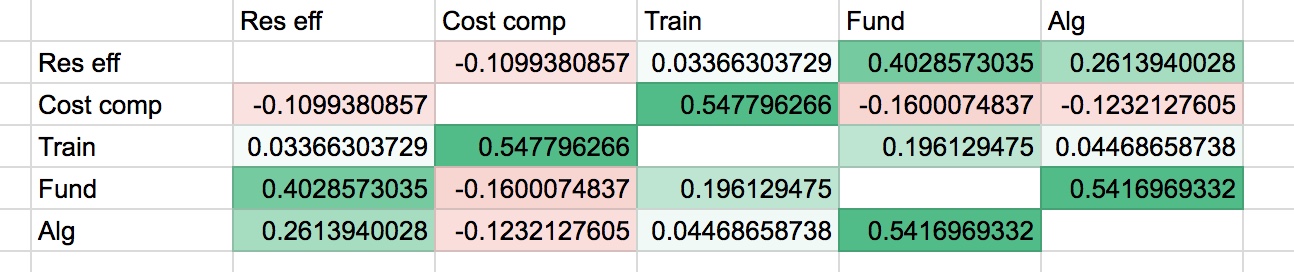
These are the Pearson product-moment correlation coefficients for the different answers, among people who received both of a pair of questions:
Impacts of HLMI
Question
Participants were asked:
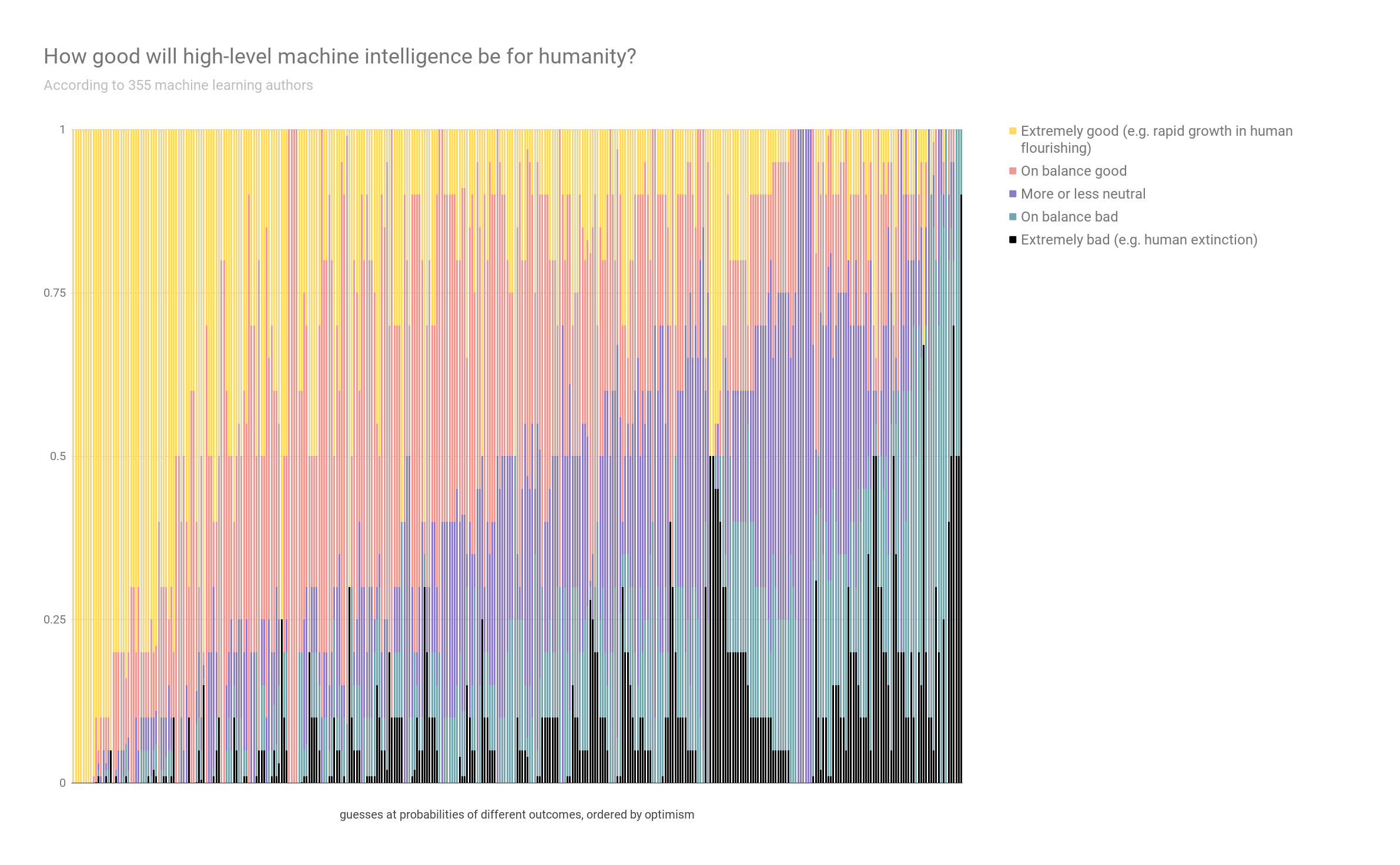
Assume for the purpose of this question that HLMI will at some point exist. How positive or negative do you expect the overall impact of this to be on humanity, in the long run? Please answer by saying how probable you find the following kinds of impact, with probabilities adding to 100%:
______ Extremely good (e.g. rapid growth in human flourishing) (1)
______ On balance good (2)
______ More or less neutral (3)
______ On balance bad (4)
______ Extremely bad (e.g. human extinction) (5)
Answers
Sensitivity of progress to changes in inputs
Question
Participants were told:
The next questions ask about the sensitivity of progress in AI capabilities to changes in inputs.
‘Progress in AI capabilities’ is an imprecise concept, so we are asking about progress as you naturally conceive of it, and looking for approximate answers.
Participants then received a random three of the following five parts:
Imagine that over the past decade, only half as much researcher effort had gone into AI research. For instance, if there were actually 1,000 researchers, imagine that there had been only 500 researchers (of the same quality).How much less progress in AI capabilities would you expect to have seen? e.g. If you think progress is linear in the number of researchers, so 50% less progress would have been made, write ’50’. If you think only 20% less progress would have been made write ’20’.
……% less
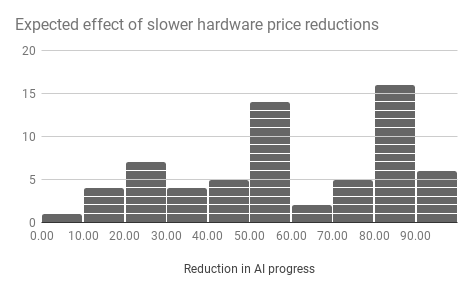
Over the last 10 years the cost of computing hardware has fallen by a factor of 20. Imagine instead that the cost of computing hardware had fallen by only a factor of 5 over that time (around half as far on a log scale). How much less progress in AI capabilities would you expect to have seen? e.g. If you think progress is linear in 1/cost, so that 1-5/20=75% less progress would have been made, write ’75’. If you think only 20% less progress would have been made write ’20’.
……% less
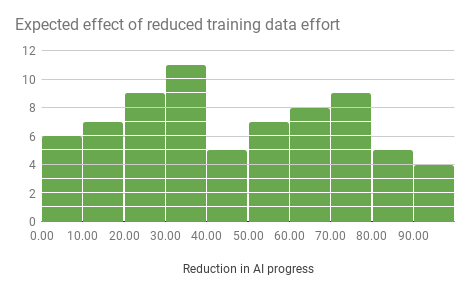
Imagine that over the past decade, there had only been half as much effort put into increasing the size and availability of training datasets. For instance, perhaps there are only half as many datasets, or perhaps existing datasets are substantially smaller or lower quality.How much less progress in AI capabilities would you expect to have seen? e.g. If you think 20% less progress would have been made, write ‘20’
……% less
Imagine that over the past decade, AI research had half as much funding (in both academic and industry labs). For instance, if the average lab had a budget of $20 million each year, suppose their budget had only been $10 million each year. How much less progress in AI capabilities would you expect to have seen? e.g. If you think 20% less progress would have been made, write ‘20’
……% less
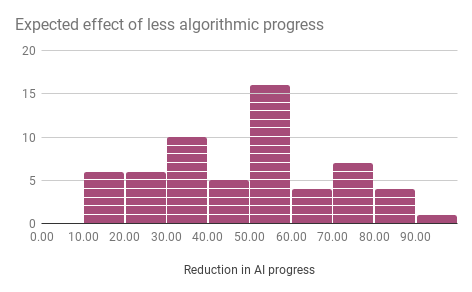
Imagine that over the past decade, there had been half as much progress in AI algorithms. You might imagine this as conceptual insights being half as frequent. How much less progress in AI capabilities would you expect to have seen? e.g. If you think 20% less progress would have been made, write ‘20’
……% less
Answers
The following five figures are histograms, showing the number of people who gave different answers to the five question parts above.


Sample sizes
| Researcher effort | Cost computing | Training data | Funding | Algorithm progress |
| 71 | 64 | 71 | 68 | 59 |
Medians
The following figure shows median answers to the above questions.
| Researcher effort | Cost computing | Training data | Funding | Algorithm progress |
| 30 | 50 | 40 | 40 | 50 |
Correlations
Outside view implied HLMI forecasts
Questions
Participants were asked:
Which AI research area have you worked in for the longest time?
————————————
How long have you worked in this area?
———years
Consider three levels of progress or advancement in this area:
A. Where the area was when you started working in it
B. Where it is now
C. Where it would need to be for AI software to have roughly human level abilities at the tasks studied in this area
What fraction of the distance between where progress was when you started working in the area (A) and where it would need to be to attain human level abilities in the area (C) have we come so far (B)?
———%
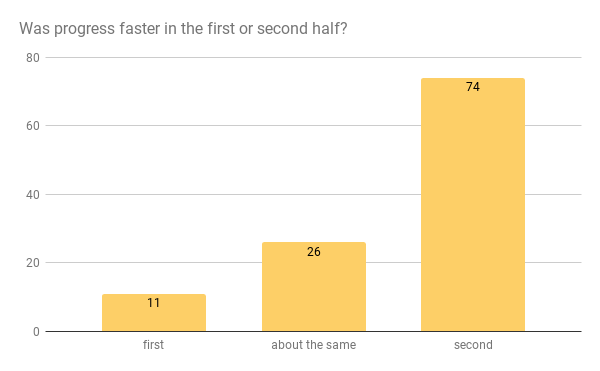
Divide the period you have worked in the area into two halves: the first and the second. In which half was the rate of progress in your area higher?
-
- The first half
- The second half
- They were about the same
Answers
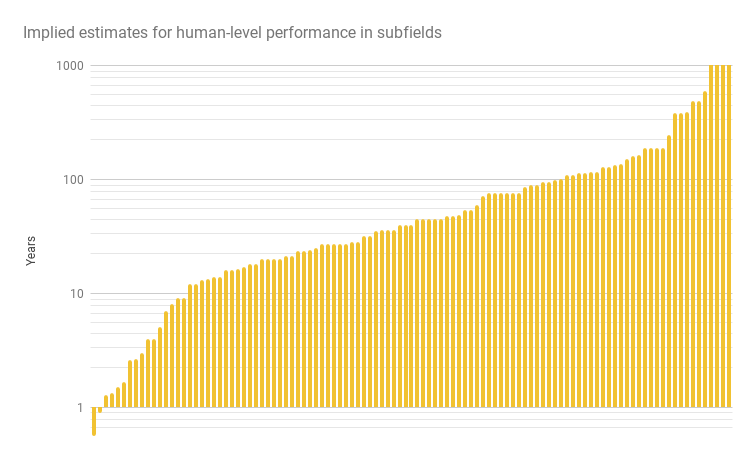
Each person told us how long they had been in their subfield, and what fraction of the remaining path to human-level performance (in their subfield) they thought had been traversed in that time. From this, we can estimate when the subfield should reach ‘human-level performance’, if progress continued at the same rate. The following graph shows those forecast dates.
Disagreements and Misunderstandings
Questions
Participants were asked:
To what extent do you think you disagree with the typical AI researcher about when HLMI will exist?
-
- A lot (17)
- A moderate amount (18)
- Not much (19)
If you disagree, why do you think that is?
_______________________________________________________
To what extent do you think people’s concerns about future risks from AI are due to misunderstandings of AI research?
-
- Almost entirely (1)
- To a large extent (2)
- Somewhat (4)
- Not much (3)
- Hardly at all (5)
What do you think are the most important misunderstandings, if there are any?
________________________________________________________
Answers
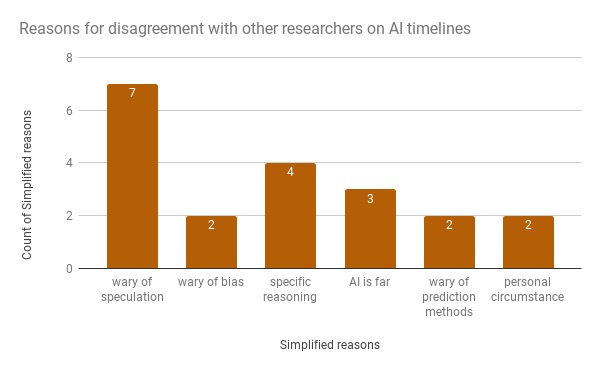
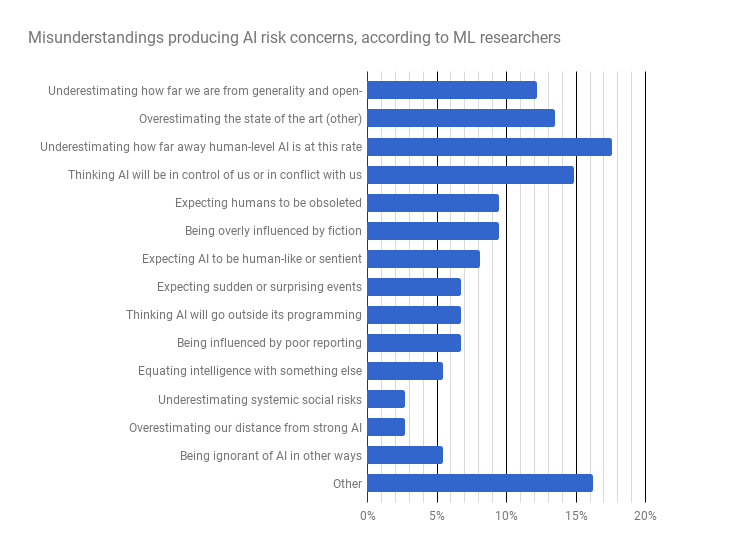
One hundred and eighteen people responded to the question on misunderstandings, and 74 of them described what they thought the most important misunderstandings were. The table and figures below show our categorization of the responses.2

| Most important misunderstandings | Number | Fraction of non-empty responses |
| Underestimate distance from generality, open-ended tasks | 9 | 12% |
| Overestimate state of the art (other) | 10 | 14% |
| Underestimate distance from AGI at this rate | 13 | 18% |
| Think AI will be in control of us or in conflict with us | 11 | 15% |
| Expect humans to be obsoleted | 7 | 9% |
| Overly influenced by fiction | 7 | 9% |
| Expect AI to be human-like or sentient | 6 | 8% |
| Expect sudden or surprising events | 5 | 7% |
| Think AI will go outside its programming | 5 | 7% |
| Influenced by poor reporting | 5 | 7% |
| Wrongly equate intelligence with something else | 4 | 5% |
| Underestimate systemic social risks | 2 | 3% |
| Overestimate distance to strong AI | 2 | 3% |
| Other ignorance of AI | 4 | 5% |
| Other | 12 | 16% |
| Empty | 44 | 59% |
Narrow tasks
Questions
Respondents were each asked one of the following two questions:
Fixed years framing:
How likely do you think it is that the following AI tasks will be feasible within the next:
- 10 years?
- 20 years?
- 50 years?
Let a task be ‘feasible’ if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.
Fixed probabilities framing:
How many years until you think the following AI tasks will be feasible with:
- a small chance (10%)?
- an even chance (50%)?
- a high chance (90%)?
Let a task be ‘feasible’ if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.
Each researcher was then presented with a random four of the following tasks:
[Rosetta] Translate a text written in a newly discovered language into English as well as a team of human experts, using a single other document in both languages (like a Rosetta stone). Suppose all of the words in the text can be found in the translated document, and that the language is a difficult one.
[Subtitles] Translate speech in a new language given only unlimited films with subtitles in the new language. Suppose the system has access to training data for other languages, of the kind used now (e.g. same text in two languages for many languages and films with subtitles in many languages).
[Translate] Perform translation about as good as a human who is fluent in both languages but unskilled at translation, for most types of text, and for most popular languages (including languages that are known to be difficult, like Czech, Chinese and Arabic).
[Phone bank] Provide phone banking services as well as human operators can, without annoying customers more than humans. This includes many one-off tasks, such as helping to order a replacement bank card or clarifying how to use part of the bank website to a customer.
[Class] Correctly group images of previously unseen objects into classes, after training on a similar labeled dataset containing completely different classes. The classes should be similar to the ImageNet classes.
[One-shot] One-shot learning: see only one labeled image of a new object, and then be able to recognize the object in real world scenes, to the extent that a typical human can (i.e. including in a wide variety of settings). For example, see only one image of a platypus, and then be able to recognize platypuses in nature photos. The system may train on labeled images of other objects. Currently, deep networks often need hundreds of examples in classification tasks1, but there has been work on one-shot learning for both classification2 and generative tasks3.
1 Lake et al. (2015). Building Machines That Learn and Think Like People
2 Koch (2015). Siamese Neural Networks for One-Shot Image Recognition
3 Rezende et al. (2016). One-Shot Generalization in Deep Generative Models
[Video scene] See a short video of a scene, and then be able to construct a 3D model of the scene that is good enough to create a realistic video of the same scene from a substantially different angle.
For example, constructing a short video of walking through a house from a video taking a very different path through the house.
[Transcribe] Transcribe human speech with a variety of accents in a noisy environment as well as a typical human can.
[Read aloud] Take a written passage and output a recording that can’t be distinguished from a voice actor, by an expert listener.
[Theorems] Routinely and autonomously prove mathematical theorems that are publishable in top mathematics journals today, including generating the theorems to prove.
[Putnam] Perform as well as the best human entrants in the Putnam competition—a math contest whose questions have known solutions, but which are difficult for the best young mathematicians.
[Go low] Defeat the best Go players, training only on as many games as the best Go players have played.
For reference, DeepMind’s AlphaGo has probably played a hundred million games of self-play, while Lee Sedol has probably played 50,000 games in his life1.
1 Lake et al. (2015). Building Machines That Learn and Think Like People
[Starcraft] Beat the best human Starcraft 2 players at least 50% of the time, given a video of the screen.
Starcraft 2 is a real time strategy game characterized by:
-
- Continuous time play
- Huge action space
- Partial observability of enemies Long term strategic play, e.g. preparing for and then hiding surprise attacks.
[Rand game] Play a randomly selected computer game, including difficult ones, about as well as a human novice, after playing the game less than 10 minutes of game time. The system may train on other games.
[Angry birds] Play new levels of Angry Birds better than the best human players. Angry Birds is a game where players try to efficiently destroy 2D block towers with a catapult. For context, this is the goal of the IJCAI Angry Birds AI competition1.
1 aibirds.org
[Atari] Outperform professional game testers on all Atari games using no game-specific knowledge. This includes games like Frostbite, which require planning to achieve sub-goals and have posed problems for deep Q-networks1, 2.
1 Mnih et al. (2015). Human-level control through deep reinforcement learning
2 Lake et al. (2015). Building Machines That Learn and Think Like People
[Atari fifty] Outperform human novices on 50% of Atari games after only 20 minutes of training play time and no game specific knowledge.
For context, the original Atari playing deep Q-network outperforms professional game testers on 47% of games1, but used hundreds of hours of play to train2.
1 Mnih et al. (2015). Human-level control through deep reinforcement learning
2 Lake et al. (2015). Building Machines That Learn and Think Like People
[Laundry] Fold laundry as well and as fast as the median human clothing store employee.
[Race] Beat the fastest human runners in a 5 kilometer race through city streets using a bipedal robot body.
[Lego] Physically assemble any LEGO set given the pieces and instructions, using non-specialized robotics hardware.
For context, Fu 20161 successfully joins single large LEGO pieces using model based reinforcement learning and online adaptation.
1 Fu et al. (2016). One-Shot Learning of Manipulation Skills with Online Dynamics Adaptation and Neural Network Priors
[Sort] Learn to efficiently sort lists of numbers much larger than in any training set used, the way Neural GPUs can do for addition1, but without being given the form of the solution.
For context, Neural Turing Machines have not been able to do this2, but Neural Programmer-Interpreters3 have been able to do this by training on stack traces (which contain a lot of information about the form of the solution).
1 Kaiser & Sutskever (2015). Neural GPUs Learn Algorithms
2 Zaremba & Sutskever (2015). Reinforcement Learning Neural Turing Machines
3 Reed & de Freitas (2015). Neural Programmer-Interpreters
[Python] Write concise, efficient, human-readable Python code to implement simple algorithms like quicksort. That is, the system should write code that sorts a list, rather than just being able to sort lists.
Suppose the system is given only:
-
- A specification of what counts as a sorted list
- Several examples of lists undergoing sorting by quicksort
[Factoid] Answer any “easily Googleable” factoid questions posed in natural language better than an expert on the relevant topic (with internet access), having found the answers on the internet.
Examples of factoid questions:
-
- “What is the poisonous substance in Oleander plants?”
- “How many species of lizard can be found in Great Britain?”
[Open quest] Answer any “easily Googleable” factual but open ended question posed in natural language better than an expert on the relevant topic (with internet access), having found the answers on the internet.
Examples of open ended questions:
-
- “What does it mean if my lights dim when I turn on the microwave?”
- “When does home insurance cover roof replacement?”
[Unkn quest] Give good answers in natural language to factual questions posed in natural language for which there are no definite correct answers.
For example:”What causes the demographic transition?”, “Is the thylacine extinct?”, “How safe is seeing a chiropractor?”
[Essay] Write an essay for a high-school history class that would receive high grades and pass plagiarism detectors.
For example answer a question like ‘How did the whaling industry affect the industrial revolution?’
[Top forty] Compose a song that is good enough to reach the US Top 40. The system should output the complete song as an audio file.
[Taylor] Produce a song that is indistinguishable from a new song by a particular artist, e.g. a song that experienced listeners can’t distinguish from a new song by Taylor Swift.
[Novel] Write a novel or short story good enough to make it to the New York Times best-seller list.
[Explain] For any computer game that can be played well by a machine, explain the machine’s choice of moves in a way that feels concise and complete to a layman.
[Poker] Play poker well enough to win the World Series of Poker.
[Laws phys] After spending time in a virtual world, output the differential equations governing that world in symbolic form.
For example, the agent is placed in a game engine where Newtonian mechanics holds exactly and the agent is then able to conduct experiments with a ball and output Newton’s laws of motion.
Answers
Fixed years framing
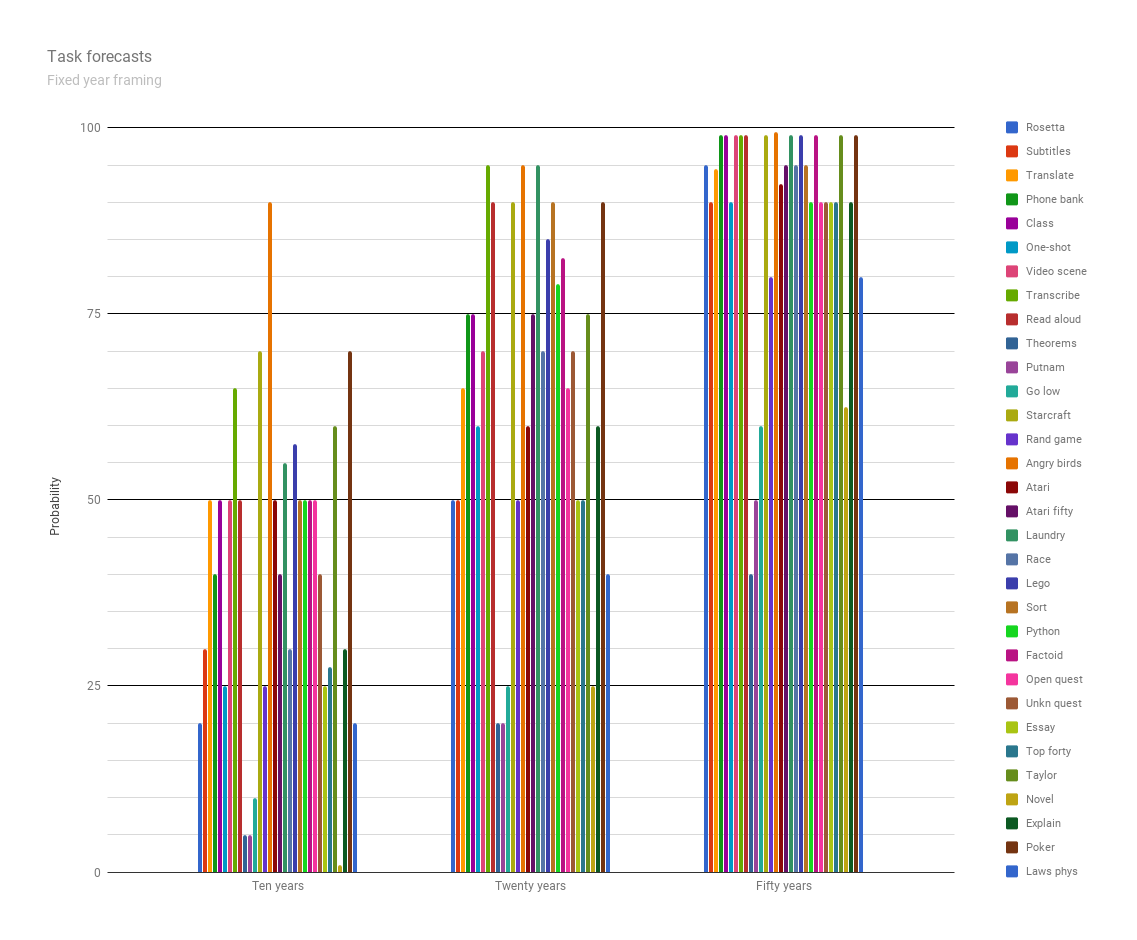
Probabilities by year (medians)
| 10 years | 20 years | 50 years | |
| Rosetta | 20 | 50 | 95 |
| Subtitles | 30 | 50 | 90 |
| Translate | 50 | 65 | 94.5 |
| Phone bank | 40 | 75 | 99 |
| Class | 50 | 75 | 99 |
| One-shot | 25 | 60 | 90 |
| Video scene | 50 | 70 | 99 |
| Transcribe | 65 | 95 | 99 |
| Read aloud | 50 | 90 | 99 |
| Theorems | 5 | 20 | 40 |
| Putnam | 5 | 20 | 50 |
| Go low | 10 | 25 | 60 |
| Starcraft | 70 | 90 | 99 |
| Rand game | 25 | 50 | 80 |
| Angry birds | 90 | 95 | 99.4995 |
| Atari | 50 | 60 | 92.5 |
| Atari fifty | 40 | 75 | 95 |
| Laundry | 55 | 95 | 99 |
| Race | 30 | 70 | 95 |
| Lego | 57.5 | 85 | 99 |
| Sort | 50 | 90 | 95 |
| Python | 50 | 79 | 90 |
| Factoid | 50 | 82.5 | 99 |
| Open quest | 50 | 65 | 90 |
| Unkn quest | 40 | 70 | 90 |
| Essay | 25 | 50 | 90 |
| Top forty | 27.5 | 50 | 90 |
| Taylor | 60 | 75 | 99 |
| Novel | 1 | 25 | 62.5 |
| Explain | 30 | 60 | 90 |
| Poker | 70 | 90 | 99 |
| Laws phys | 20 | 40 | 80 |
Fixed probabilities framing
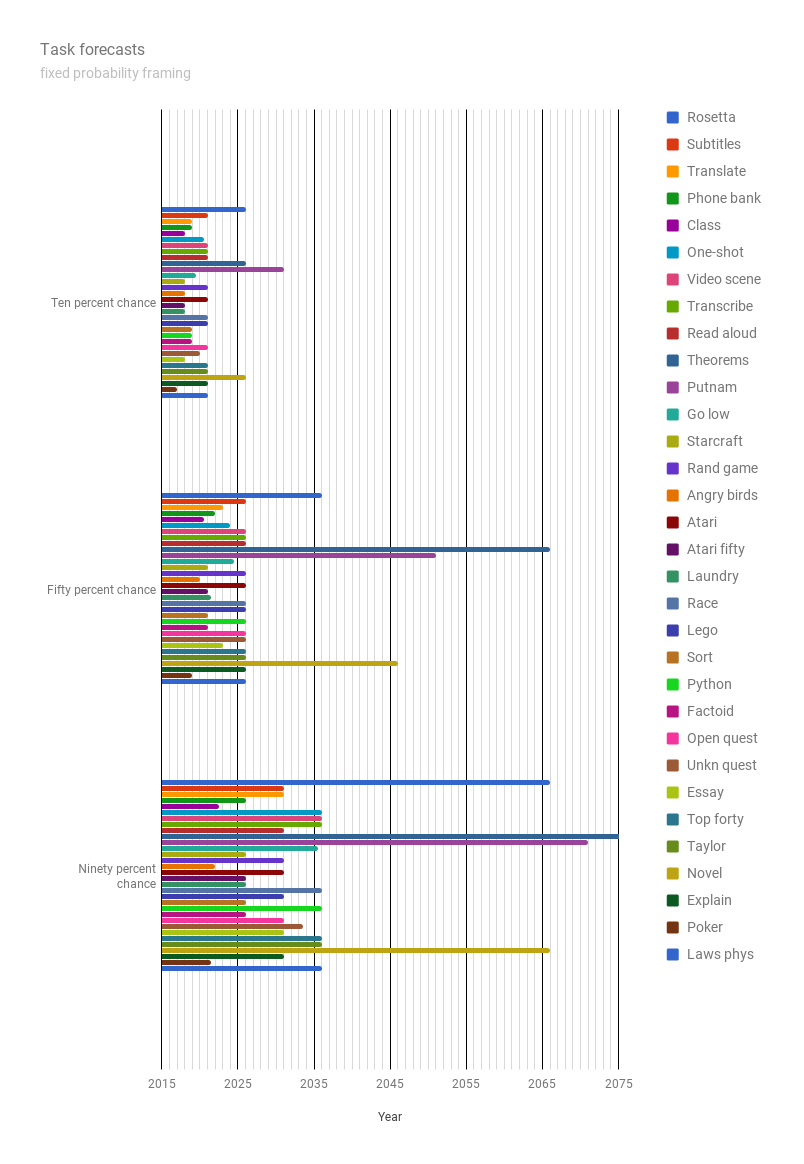
Years by probability (medians)
| 10 percent | 50 percent | 90 percent | |
| Rosetta | 10 | 20 | 50 |
| Subtitles | 5 | 10 | 15 |
| Translate | 3 | 7 | 15 |
| Phone bank | 3 | 6 | 10 |
| Class | 2 | 4.5 | 6.5 |
| One-shot | 4.5 | 8 | 20 |
| Video scene | 5 | 10 | 20 |
| Transcribe | 5 | 10 | 20 |
| Read aloud | 5 | 10 | 15 |
| Theorems | 10 | 50 | 90 |
| Putnam | 15 | 35 | 55 |
| Go low | 3.5 | 8.5 | 19.5 |
| Starcraft | 2 | 5 | 10 |
| Rand game | 5 | 10 | 15 |
| Angry birds | 2 | 4 | 6 |
| Atari | 5 | 10 | 15 |
| Atari fifty | 2 | 5 | 10 |
| Laundry | 2 | 5.5 | 10 |
| Race | 5 | 10 | 20 |
| Lego | 5 | 10 | 15 |
| Sort | 3 | 5 | 10 |
| Python | 3 | 10 | 20 |
| Factoid | 3 | 5 | 10 |
| Open quest | 5 | 10 | 15 |
| Unkn quest | 4 | 10 | 17.5 |
| Essay | 2 | 7 | 15 |
| Top forty | 5 | 10 | 20 |
| Taylor | 5 | 10 | 20 |
| Novel | 10 | 30 | 50 |
| Explain | 5 | 10 | 15 |
| Poker | 1 | 3 | 5.5 |
| Laws phys | 5 | 10 | 20 |
Safety
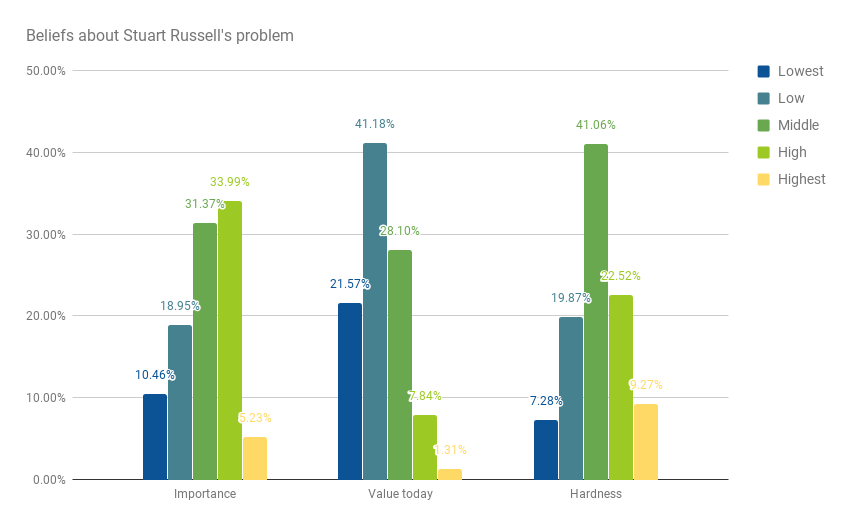
Stuart Russell’s problem
Question
Participants were asked:
Stuart Russell summarizes an argument for why highly advanced AI might pose a risk as follows:
The primary concern [with highly advanced AI] is not spooky emergent consciousness but simply the ability to make high-quality decisions. Here, quality refers to the expected outcome utility of actions taken […]. Now we have a problem:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. This is essentially the old story of the genie in the lamp, or the sorcerer’s apprentice, or King Midas: you get exactly what you ask for, not what you want.
Do you think this argument points at an important problem?
-
- No, not a real problem.
- No, not an important problem.
- Yes, a moderately important problem.
- Yes, a very important problem.
- Yes, among the most important problems in the field.
How valuable is it to work on this problem today, compared to other problems in AI?
-
- Much less valuable
- Less valuable
- As valuable as other problems
- More valuable
- Much more valuable
How hard do you think this problem is compared to other problems in AI?
-
- Much easier
- Easier
- As hard as other problems
- Harder
- Much harder
Answers
General safety
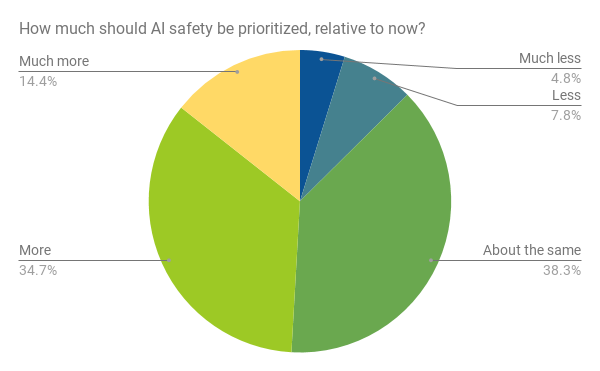
Question
Participants were asked:
Let ‘AI safety research’ include any AI-related research that, rather than being primarily aimed at improving the capabilities of AI systems, is instead primarily aimed at minimizing potential risks of AI systems (beyond what is already accomplished for those goals by increasing AI system capabilities).
Examples of AI safety research might include:
-
- Improving the human-interpretability of machine learning algorithms for the purpose of improving the safety and robustness of AI systems, not focused on improving AI capabilities
- Research on long-term existential risks from AI systems
- AI-specific formal verification research
- Policy research about how to maximize the public benefits of AI
How much should society prioritize AI safety research, relative to how much it is currently prioritized?
-
- Much less
- Less
- About the same
- More
- Much more
Answers
Paper
Some results are reported in When Will AI Exceed Human Performance? Evidence from AI Experts3.
Some notes on interpreting the paper4:
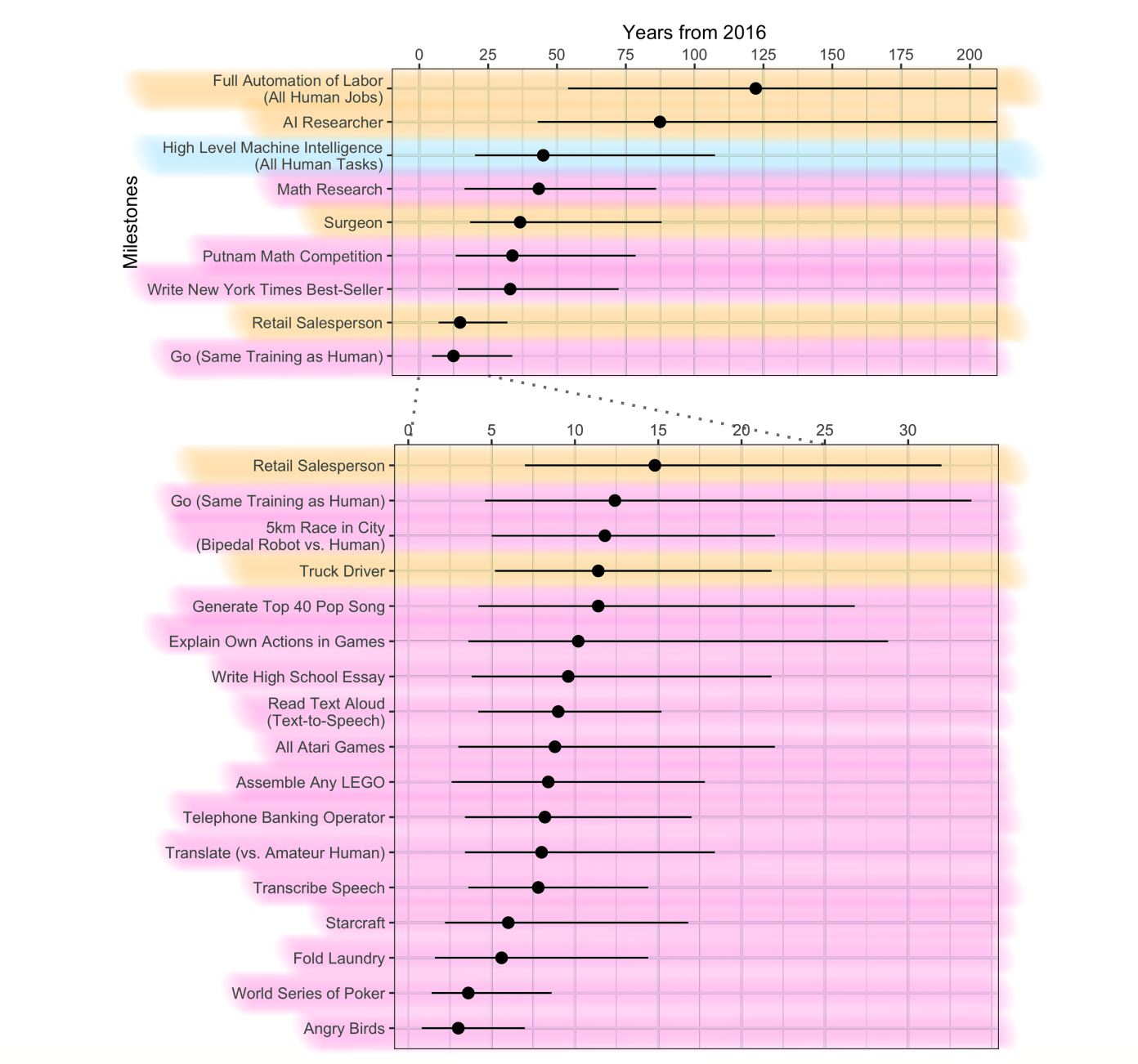
- The milestones in the timeline and in the abstract are from three different sets of questions. There seems to be a large framing effect between two of them—full automation of labor is logically required to be before HLMI, and yet it is predicted much later—and it is unclear whether people answer the third set of questions (about narrow tasks) more like the one about HLMI or more like the one about occupations. Plus even if there were no framing effect to worry about, we should expect milestones about narrow tasks to be much earlier than milestones about very similar sounding occupations. For instance, if there were an occupation ‘math researcher’, it should be later than the narrow task summarized here as ‘math research’. So there is a risk of interpreting the figure as saying AI research is harder than math research, when really the ‘-er’ is all-important. So to help avoid confusion, here is the timeline colored in by which set of questions each milestone came from. The blue one was asked on its own. The orange ones were always asked together: first all four occupations, then they were asked for an occupation they expected to be very late, and when they expected it, then full automation of labor. The pink milestones were randomized, so that each person got four. There are a lot more pink milestones not included here, but included in the long table at the end of the paper.
- In Figure 2 and Table S5 I believe the word ‘median’ means we are talking about the ‘50% chance of occurring’ number, and the dates given are this ‘median’ (50% chance) date for a distribution that was made by averaging together all of the different people’s distributions (or what we guess their distributions are like from three data points).

Authors: Katja Grace, John Salvatier, Allan Dafoe, Baobao Zhang, and Owain Evans. This page is an extended analyses of research published in Grace et al 2017 5, so includes research contributions from all authors, but Katja compiled and described these, and added additional figures and analyses, so composition decisions and opinion reflect her views and not necessarily those of the group, and much of the specific analysis has not been vetted by the group in this form.
Suggested citation:
Grace, Katja, John Salvatier, Allan Dafoe, Baobao Zhang, and Owain Evans. “2016 Expert Survey on Progress in AI.” In AI Impacts, December 14, 2016. https://aiimpacts.org/2016-expert-survey-on-progress-in-ai/.
Notes
- A small number of respondents may have answered a slightly different version of this question in an initial round, in which case those answers are not included here.
- One person has categorized these responses, and another has checked and corroborated their categorizations.
- Grace, Katja, John Salvatier, Allan Dafoe, Baobao Zhang, and Owain Evans. “When Will AI Exceed Human Performance? Evidence from AI Experts.” ArXiv:1705.08807 [Cs], May 3, 2018. http://arxiv.org/abs/1705.08807.
- Originally in an AI Impacts blog post:
AI Impacts. “Some Survey Results!,” June 8, 2017. https://aiimpacts.org/some-survey-results/.
- Grace, Katja, John Salvatier, Allan Dafoe, Baobao Zhang, and Owain Evans. “When Will AI Exceed Human Performance? Evidence from AI Experts.” ArXiv:1705.08807 [Cs], 2017. http://arxiv.org/abs/1705.08807.


Awesome summary, check this out you can create AI content with this website carboncopy.pro
Thank you for sharing, always excited to see the progres sof AI